
Architecture Overview:

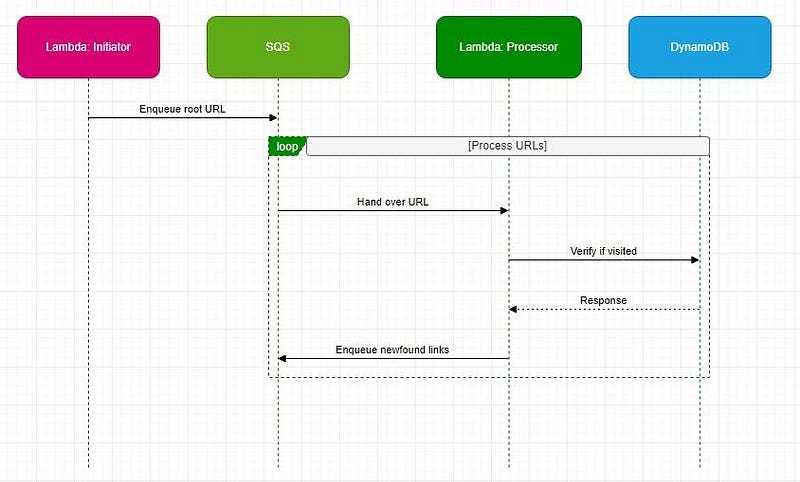
The main components of our serverless crawler are Lambda functions, an SQS queue, and a DynamoDB table. Here’s a breakdown:
- Lambda: Two distinct functions — one for initiating the crawl and another for the actual processing.
- SQS: Manages pending crawl tasks as a buffer and task distributor.
- DynamoDB: Stores visited URLs, ensuring we avoid redundant visits.
Workflow & Logic Rationale:
Initiation:
Starting Point (Root URL):
Logic: The crawl starts with a root URL, e.g., “www.shanoj.com”.
Rationale: A defined beginning allows the crawler to commence in a guided manner.
Uniqueness with UUID:
Logic: A unique run ID is generated for every crawl to ensure distinction.
Rationale: These guards against potential data overlap in the case of concurrent crawls.
Avoiding Redundant Visits:
Logic: The root URL is pre-emptively marked as “visited”.
Rationale: This step is integral to maximizing efficiency by sidestepping repeated processing.
The URL then finds its way to SQS, awaiting crawling.
Processing:
Link Extraction:
Logic: A secondary Lambda function polls SQS for URLs. Once a URL is retrieved, the associated webpage is fetched. All the links are identified and extracted within this webpage for further processing.
Rationale: Extracting all navigable paths from our current location is pivotal to web exploration.
Depth-First Exploration Strategy:
Logic: Extracted links undergo a check against DynamoDB. If previously unvisited, they’re designated as such in the database and enqueued back into SQS.
Rationale: This approach delves deep into one link’s pathways before backtracking, optimizing resource utilization.
Special Considerations:
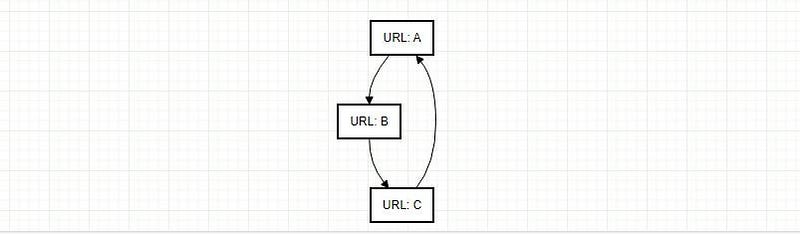
A challenge for web crawlers is the potential for link loops, which can usher in infinite cycles. By verifying the “visited” status of URLs in DynamoDB, we proactively truncate these cycles.
Back-of-the-Envelope Estimation for Web Crawling:
1. Data Download:
- Webpages per month: 1 billion
- The average size of a webpage: 500 KB
Total data downloaded per month:
1,000,000,000 (webpages) × 500 KB = 500,000,000,000 KB
or 500 TB (terabytes) of data every month.
2. Lambda Execution:
Assuming that the Lambda function needs to be invoked for each webpage to process and extract links:
- Number of Lambda executions per month: 1 billion
(One would need to further consider the execution time for each Lambda function and the associated costs)
3. DynamoDB Storage:
Let’s assume that for each webpage, we store only the URL and some metadata which might, on average, be 1 KB:
- Total storage needed for DynamoDB per month:
- 1,000,000,000 (webpages) × 1 KB = 1,000,000,000 KB
- or 1 TB of data storage every month.
(However, if you’re marking URLs as “visited” and removing them post the crawl, then the storage might be significantly less on a persistent basis.)
4. SQS Messages:
Each webpage URL to be crawled would be a message in SQS:
- Number of SQS messages per month: 1 billion
The system would require:
- 500 TB of data storage and transfer capacity for the actual web pages each month.
- One billion Lambda function executions monthly for processing.
- About 1 TB of storage in DynamoDB might vary based on retention and removal strategies.
- One billion SQS messages to manage the crawl queue.
Stackademic
Thank you for reading until the end. Before you go:
- Please consider clapping and following the writer! 👏
- Follow us on Twitter(X), LinkedIn, and YouTube.
- Visit Stackademic.com to find out more about how we are democratizing free programming education around the world.
