

Scaling an application is a challenging task. To scale effectively, you often need to increase the number of web servers, application servers, and database servers. However, this can make your architecture complex due to the need for high performance and scalability to serve thousands of concurrent users.
Horizontal scaling of the database layer typically involves sharding, which adds further complexity and makes it difficult to manage.
In general, Space-Based Architecture (SBA) addresses the challenge of creating highly scalable and elastic systems capable of handling a vast number of concurrent users and operations. Traditional architectures often struggle with performance bottlenecks due to direct interactions with the database for transactional data, leading to limitations in scalability and elasticity.
What is Space-Based Architecture (SBA)?
In Space-Based Architecture (SBA), you scale your application by removing the database and instead using memory grids to manage the data. Instead of scaling a particular tier in your application, you scale the entire architecture together as a unified process. SBA is widely used in distributed computing to increase the scalability and performance of a solution. This architecture is based on the concept of a tuple space.
Note: A tuple space is a shared memory object that provides operations to store and retrieve ordered sets of data, called tuples. It is an implementation of the associative memory paradigm for parallel/distributed computing, allowing multiple processes to access and manipulate tuples concurrently.
Goals of SBA
High Scalability and Elasticity:
· Efficiently managing and processing millions of concurrent users and transactions without direct database interactions.
· Enabling rapid scaling from a small number of users to hundreds of thousands or more within milliseconds.
Performance Optimization:
· Reducing latency by utilizing in-memory data grids and caching mechanisms instead of direct database reads and writes.
· Ensuring quick data access times measured in nanoseconds for a seamless user experience.
Eventual Consistency:
· Maintaining eventual consistency across distributed processing units through replicated caching and asynchronous data writes to the database.
Decoupling Database Dependency:
· Minimizing the dependency on the database for real-time transaction processing to prevent database bottlenecks and improve system responsiveness.
Handling High Throughput:
Managing high throughput demands without overwhelming the database by leveraging in-memory data replication and distributed processing units.
Key Components of SBA
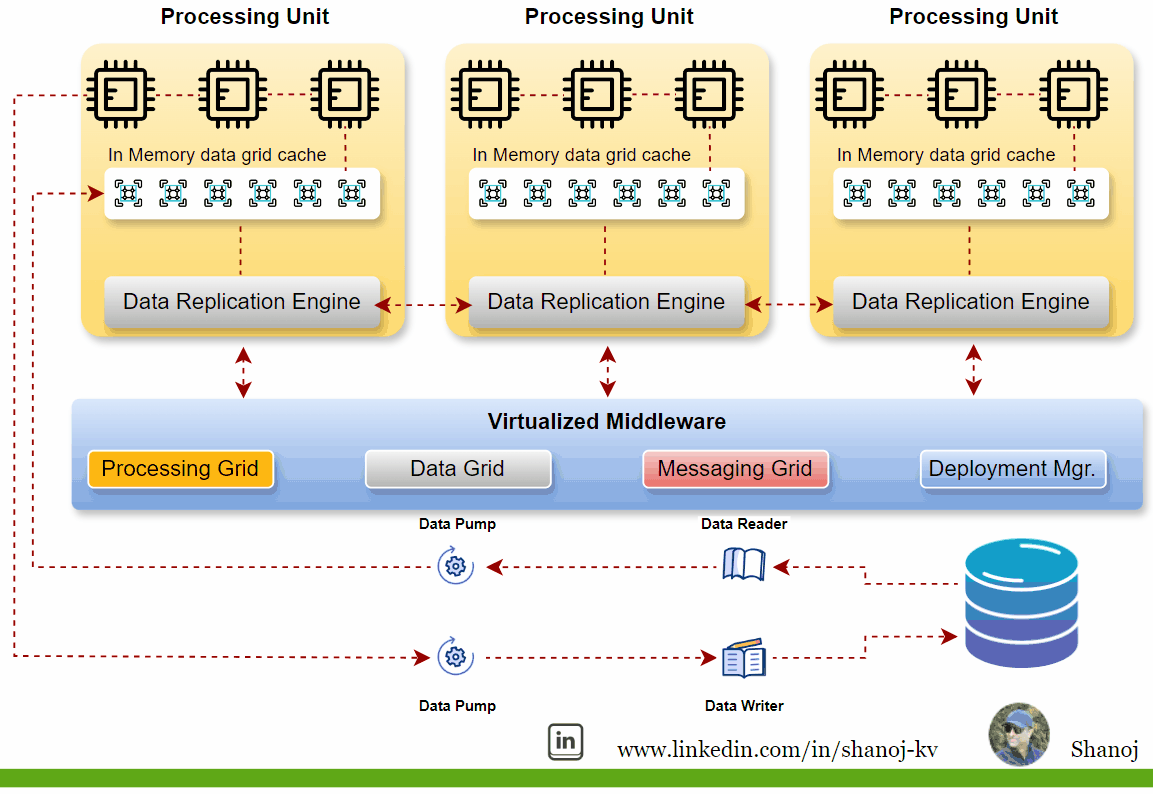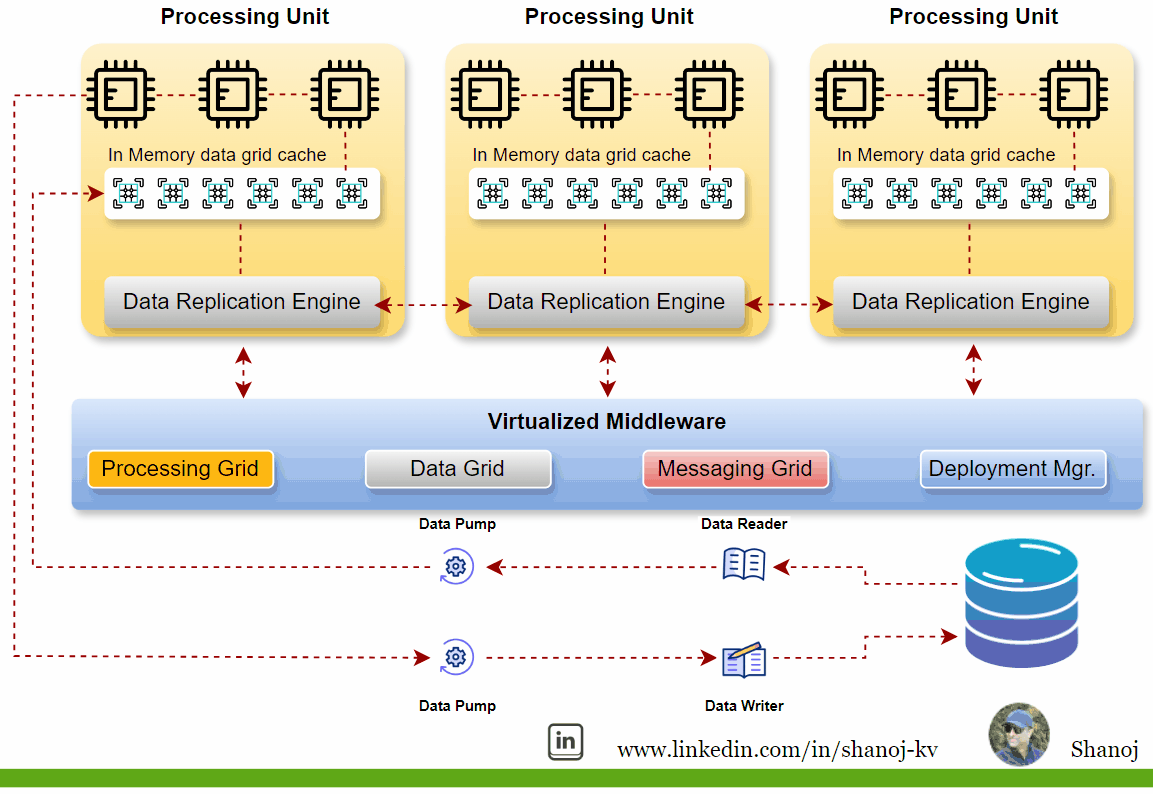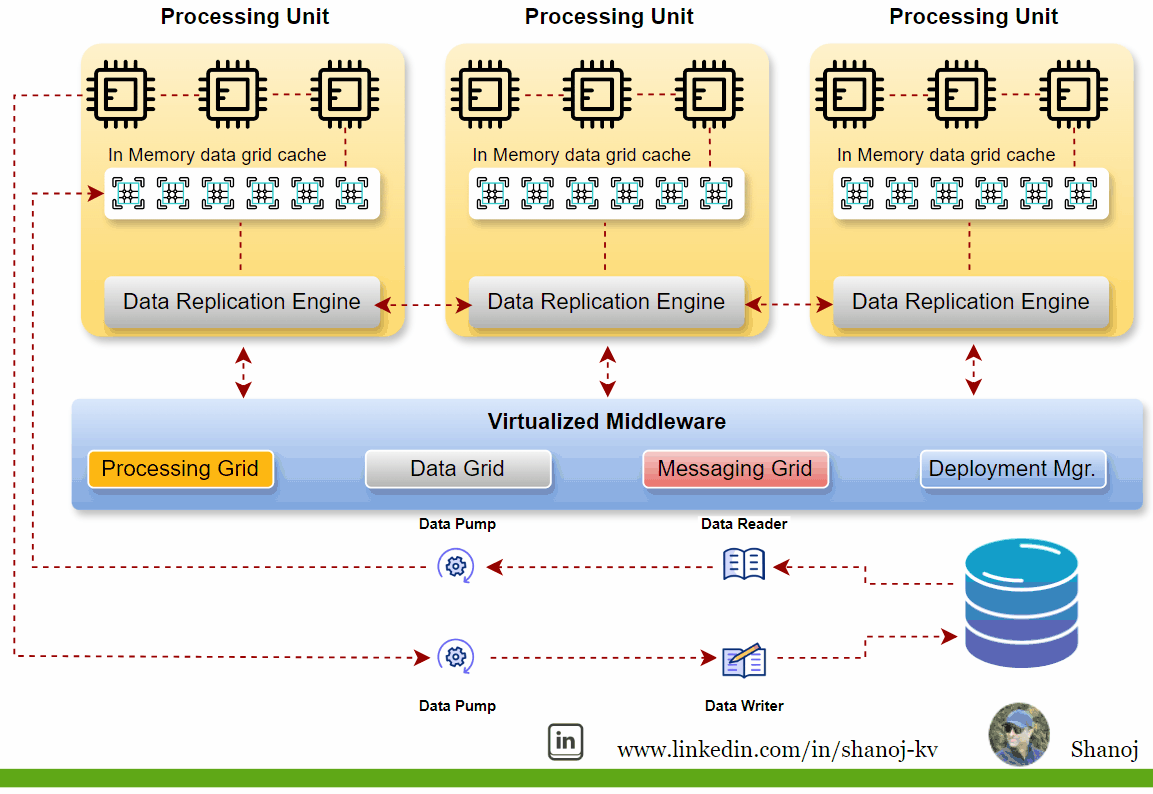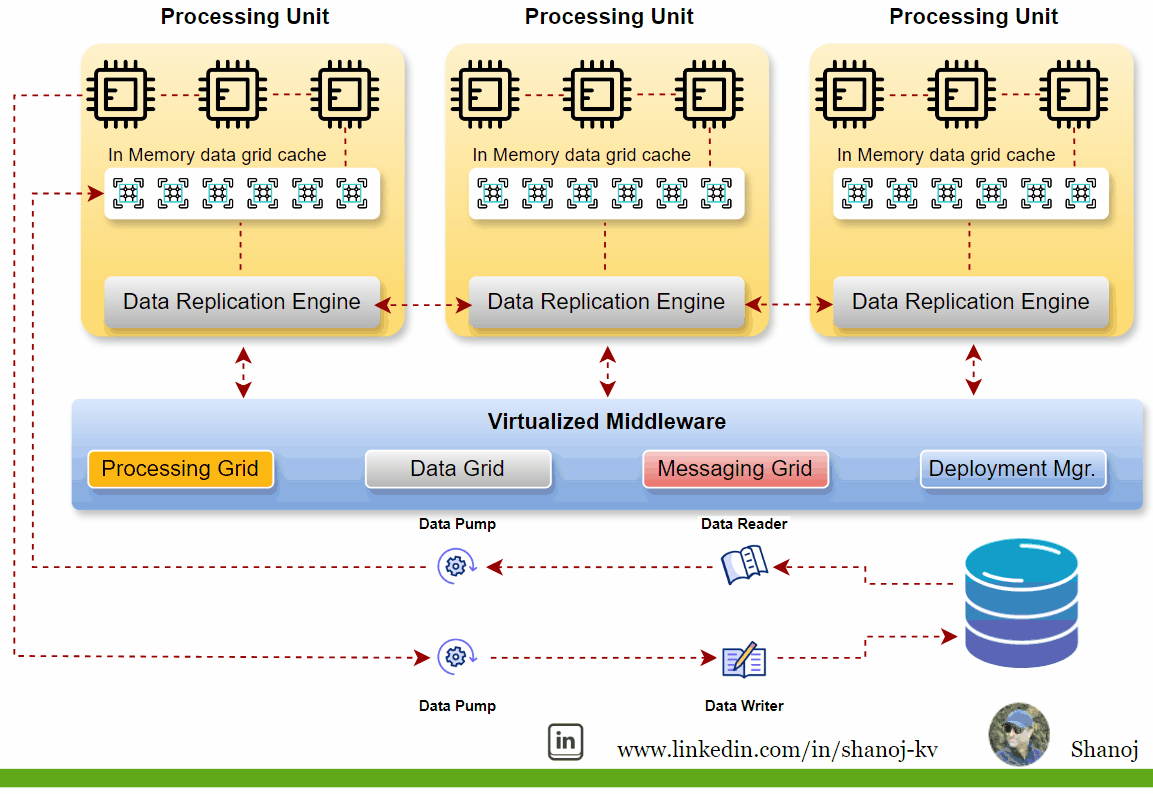
Processing Units (PU):
These are individual nodes or containers that encapsulate the processing logic and the data they operate on. Each PU is responsible for executing business logic and can be replicated or partitioned for scalability and fault tolerance. They typically include web-based components, backend business logic, an in-memory data grid, and a replication engine.
Virtualized Middleware:
This layer handles shared infrastructure concerns and includes:
· Data Grid: A crucial component that allows requests to be assigned to any available processing unit, ensuring high performance and reliability. The data grid is responsible for synchronizing data between the processing units by building the tuple space.
· Messaging Grid: Manages the flow of incoming transactions and communication between services.
· Processing Grid: Enables parallel processing of events among different services based on the master/worker pattern.
· Deployment Manager: Manages the startup and shutdown of PUs, starts new PUs to handle additional load, and shuts down PUs when no longer needed.
· Data Pumps and Data Readers/Writers: Data pumps marshal data between the database and the processing units, ensuring consistent data updates across nodes.
Now you might be naturally thinking, what makes SBA different from a traditional memory cache database?
Differences Between SBA and Memory Cache Databases
Data Consistency:
· SBA: Uses an eventual consistency model, where updates are asynchronously propagated across nodes, ensuring eventual convergence without the need for immediate consistency, which can introduce significant performance overhead.
· Memory Cache Database: Typically uses strong consistency models, ensuring immediate consistency across all nodes, which can impact performance.
Scalability:
· SBA: Achieves linear scalability by adding more processing units (PUs) as needed, ensuring the system can handle increasing workloads without performance degradation.
· Memory Cache Database: Scalability is often limited by the underlying database architecture and can be more complex to scale horizontally.
Data Replication:
· SBA: Replicates data across multiple nodes to ensure fault tolerance and high availability. In the event of a node failure, the system can seamlessly recover by accessing replicated data from other nodes.
· Memory Cache Database: Data replication is used for performance and availability but can be more complex to manage and maintain consistency.
Data Grid:
· SBA: Utilizes a distributed data grid that allows requests to be assigned to any available processing unit, ensuring high performance and reliability.
· Memory Cache Database: Typically uses a centralized cache that can become a bottleneck as the system scales.
Processing:
· SBA: Enables parallel processing across multiple nodes, leading to improved throughput and response times.
· Memory Cache Database: Processing is typically done within the database or cache layer, which can be less scalable and efficient.
Deployment:
· SBA: Supports elastic scalability by adding or removing nodes as needed, ensuring the system can handle increased workloads without compromising performance or data consistency.
· Memory Cache Database: Deployment and scaling can be more complex and often require significant infrastructure changes.
Cost:
· SBA: Can be more cost-effective by leveraging distributed computing and in-memory processing, reducing the need for expensive hardware and infrastructure upgrades.
· Memory Cache Database: Can be more expensive due to the need for high-performance hardware and infrastructure to support the cache layer.
Now you might be wondering, is SBA suitable for every scenario?
Limitations of SBA
High Data Synchronization and Consistency Requirements:
Systems that require immediate data consistency and high synchronization across all components will not benefit from SBA due to its eventual consistency model.
The delay in synchronizing data with the database may not meet the needs of applications requiring real-time consistency.
Large Volumes of Transactional Data:
Applications needing to store and manage massive amounts of transactional data (e.g., terabytes) are not suitable for SBA.
Keeping such large volumes of data in memory is impractical and may exceed the memory capacity of available hardware.
Budget and Time Constraints:
Projects with strict budget and time constraints are likely to overrun their resources due to the technical complexity of implementing SBA.
The initial setup and implementation are resource-intensive, requiring significant investment in both time and money.
Technical Complexity:
The high technical complexity of SBA makes it challenging to implement, maintain, and troubleshoot.
Organizations lacking the necessary expertise and experience may find it difficult to manage the intricacies of SBA.
Cost Considerations:
The cost of maintaining in-memory data grids and replicated caching can be prohibitive, especially for smaller organizations or projects with limited budgets.
The infrastructure required to support SBA’s scalability and performance may be expensive to acquire and maintain.
Limited Agility:
SBA offers limited agility compared to other architectural styles due to its complex setup and eventual consistency model.
Changes and updates to the system may require significant effort and coordination across distributed processing units.
Now, let’s dive into some use cases and solutions that demonstrate the power of SBA.
Use Cases and Solutions
Space-Based Architecture (SBA) addresses several critical challenges that traditional architectures face, particularly in high-transaction, high-availability, and variable load environments.
Scalability Bottlenecks:
· Problem: Traditional architectures often struggle to scale horizontally due to limitations in centralized data storage and processing.
· Solution: SBA enables horizontal scalability by distributing processing units (PUs) across multiple nodes. Each PU can handle a portion of the workload independently, allowing the system to scale out by simply adding more PUs.
High Availability and Fault Tolerance:
· Problem: Ensuring high availability and fault tolerance is challenging in monolithic or tightly coupled systems.
· Solution: SBA enhances fault tolerance through redundancy and data replication. Each PU operates independently, and data is replicated across multiple PUs. If one PU fails, others can take over, ensuring continuous availability and minimal downtime.
Performance Issues:
· Problem: Traditional systems often rely heavily on relational databases, leading to performance bottlenecks due to slow disk I/O and limited scalability of single-node databases.
· Solution: SBA leverages in-memory data grids, which provide faster data access and reduce the dependency on disk-based storage, significantly improving response times and overall system performance.
Handling Variable and Unpredictable Loads:
· Problem: Many applications experience variable and unpredictable workloads, such as seasonal spikes in e-commerce or fluctuating traffic in social media platforms.
· Solution: SBA’s elastic nature allows it to automatically adjust to varying loads by adding or removing PUs as needed, ensuring the system can handle peak loads without performance degradation.
Reducing Single Points of Failure:
· Problem: Centralized components, such as single database servers or monolithic application servers, can become single points of failure.
· Solution: SBA decentralizes processing and storage, eliminating single points of failure. Each PU can function independently, and the system can continue to operate even if some PUs fail.
Complex Data Management:
· Problem: Managing large volumes of data and ensuring its consistency, availability, and partitioning across a distributed system can be complex.
· Solution: SBA uses distributed data stores and in-memory data grids to manage data efficiently, ensuring data consistency and availability through replication and partitioning strategies.
Simplifying Deployment and Maintenance:
· Problem: Deploying and maintaining traditional monolithic applications can be cumbersome.
· Solution: SBA’s modular nature simplifies deployment and maintenance. Each PU can be developed, tested, and deployed independently, reducing the risk of system-wide issues during updates or maintenance.
Latency and Real-Time Processing:
· Problem: Real-time processing and low-latency requirements are difficult to achieve with traditional architectures.
· Solution: SBA’s use of in-memory data grids and asynchronous messaging grids ensures low latency and real-time processing capabilities, crucial for applications requiring immediate data processing and response.
Space-Based Architecture addresses several significant challenges faced by traditional architectures, making it an ideal choice for applications requiring high scalability, performance, availability, and resilience. By distributing processing and data management across independent units, SBA ensures that systems can handle modern demands efficiently and effectively.
Stackademic 🎓
Thank you for reading until the end. Before you go:
- Please consider clapping and following the writer! 👏
- Follow us X | LinkedIn | YouTube | Discord
- Visit our other platforms: In Plain English | CoFeed | Differ
- More content at Stackademic.com

























