Apache Flink is a robust, open-source data processing framework that handles large-scale data streams and batch-processing tasks. One of the critical features of Flink is its architecture, which allows it to manage both batch and stream processing in a single system.
Consider a retail company that wishes to analyse sales data in real-time. They can use Flink’s stream processing capabilities to process sales data as it comes in and batch processing capabilities to analyse historical data.
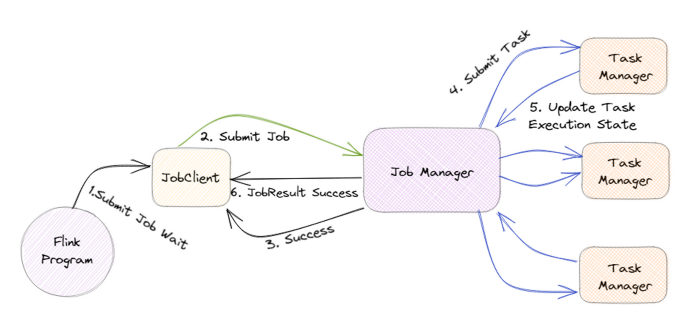
The JobManager is the central component of Flink’s architecture, and it is in charge of coordinating the execution of Flink jobs.
For example, if a large amount of data is submitted to Flink, the JobManager will divide it into smaller tasks and assign them to TaskManagers.
TaskManagers are responsible for executing the assigned tasks, and they can run on one or more nodes in a cluster. The TaskManagers are connected to the JobManager via a high-speed network, allowing them to exchange data and task information.
For example, when a TaskManager completes a task, it will send the results to the JobManager, who will then assign the next task.
Flink also has a distributed data storage system called the Distributed Data Management (DDM) system. It allows for storing and managing large data sets in a distributed manner across all the nodes in a cluster.
For example, imagine a company that wants to store and process petabytes of data, they can use Flink’s DDM system to store the data across multiple nodes, and process it in parallel.
Flink also has a built-in fault-tolerance mechanism, allowing it to recover automatically from failures. This is achieved by maintaining a consistent state across all the nodes in the cluster, which allows the system to recover from a failure by replaying the state from a consistent checkpoint.
For example, if a node goes down, Flink can automatically recover the data and continue processing without any interruption.
In addition, Flink also has a feature called “savepoints”, which allows users to take a snapshot of the state of a job at a particular point in time and later use this snapshot to restore the job to the same state.
For example, imagine a company is performing an update to their data processing pipeline and wants to test the new pipeline with the same data. They can use a savepoint to take a snapshot of the state of the job before making the update and then use that snapshot to restore the job to the same state for testing.
Flink also supports a wide range of data sources and sinks, including Kafka, Kinesis, and RabbitMQ, which allows it to integrate with other systems in a big data ecosystem easily.
For example, a company can use Flink to process streaming data from a Kafka topic and then sink the processed data into a data lake for further analysis.
The critical feature of Flink is that it handles batch and stream processing in a single system. To support this, Flink provides two main APIs: the Dataset API and the DataStream API.
The Dataset API is a high-level API for Flink that allows for batch processing of data. It uses a type-safe, object-oriented programming model and offers a variety of operations such as filtering, mapping, and reducing, as well as support for SQL-like queries. This API is handy for dealing with a large amount of data and is well suited for use cases such as analyzing historical sales data of a retail company.
On the other hand, the DataStream API is a low-level API for Flink that allows for real-time data stream processing. It uses a functional programming model and offers a variety of operations such as filtering, mapping, and reducing, as well as support for windowing and event time processing. This API is particularly useful for dealing with real-time data and is well-suited for use cases such as real-time monitoring and analysis of sensor data.
In conclusion, Apache Flink’s architecture is designed to handle large-scale data streams and batch-processing tasks in a single system. It provides a distributed data storage system, built-in fault tolerance and savepoints, and support for a wide range of data sources and sinks, making it an attractive choice for big data processing. With its powerful and flexible architecture, Flink can be used in various use cases, from real-time data processing to batch data processing, and can be easily integrated with other systems in a big data ecosystem.
The Leader’s Compass: Situational Awareness from Ancient Wisdom to Modern Practice
Situational awareness — the ability to perceive, comprehend, and anticipate changes in your environment — forms the bedrock of effective leadership. Whether guiding a family, managing a team, or leading an organization, leaders often falter not from lack of intelligence or vision, but from being disconnected from the realities around them.
This disconnect manifests in leaders who miss crucial social cues, fail to adapt to changing circumstances, or remain blind to emerging threats and opportunities. Across centuries, from ancient battlefields to modern boardrooms, the wisdom remains consistent: a leader must be acutely aware of their situation to navigate successfully.
Ancient Wisdom on Awareness
Sun Tzu: Know Yourself and Your Environment
“If you know the enemy and know yourself, you need not fear the result of a hundred battles.”
Over 2,000 years ago, the Chinese general Sun Tzu identified comprehensive awareness as the foundation of victory. His teaching emphasizes that leaders who understand both their own capabilities and the challenges before them will consistently succeed.
Sun Tzu also introduced the concept of “zhao shi” (situation-making) — the ability to create and leverage favorable circumstances rather than merely responding to them. This dimension of situational awareness involves actively shaping conditions to your advantage.
For today’s leader, this translates to thoroughly understanding your team’s strengths and limitations while accurately assessing the challenges you face. When you possess this dual awareness, you can anticipate moves and consequences rather than reacting blindly. Leaders who lack this perspective may occasionally succeed through luck but will inevitably face defeat when their incomplete understanding leads to poor decisions.
Marcus Aurelius: Adapt to Reality and Care for People
“Adapt yourself to the environment in which your lot has been cast, and show true love to the fellow-mortals with whom destiny has surrounded you.”
As Emperor of Rome, Marcus Aurelius advised himself to accept and adapt to circumstances while genuinely caring for those around him. This Stoic counsel addresses situational awareness at a personal level: effective leaders must not deny reality but instead understand and adapt to their environment while maintaining authentic connections with others.
Marcus Aurelius demonstrated this philosophy during significant crises, such as the Avidius Cassius rebellion. When faced with this attempted usurpation, he remained calm and rational, responding with measured action rather than reactive emotion — a perfect example of situational awareness in practice.
Leaders often lack awareness because they resist uncomfortable truths about their situation — whether market shifts or team tensions. By embracing reality with humility and extending compassion to others, leaders can respond appropriately to changing dynamics. In practice, this means noticing a team member’s distress and adjusting expectations, or recognizing industry changes and pivoting strategy accordingly.
Machiavelli: Change Your Approach as Times Change
“Whosoever desires constant success must change his conduct with the times.”
Renaissance political philosopher Machiavelli observed that rigid leadership fails when times change. His insight highlights situational awareness as the ability to sense and respond to shifting conditions. The message is clear: fortune and circumstances constantly evolve, and only leaders alert to these changes can maintain success.
In “The Prince,” Machiavelli elaborates on this concept, explaining that flexibility in leadership strategies isn’t merely beneficial — it’s essential for maintaining power and influence in an ever-changing environment. He provides historical examples of leaders who succeeded or failed based on their ability to adapt their approaches to new circumstances.
For contemporary leaders, this might mean adjusting management styles as teams evolve or embracing new technologies rather than clinging to familiar approaches. Leaders who lack situational awareness often persist with once-effective methods even as evidence mounts that the landscape has transformed. Machiavelli’s wisdom carries a stark warning: adapt or perish.
Modern Insights on Leadership Awareness
Jocko Willink: Control the Situation, Don’t Let It Control You
“Instead of letting the situation dictate our decisions, we must dictate the situation.”
Former Navy SEAL commander Jocko Willink emphasizes that situational awareness isn’t passive observation but the foundation for decisive action. Drawing from high-pressure combat experience, Willink urges leaders to maintain such keen awareness of their environment that they can shape outcomes rather than merely react.
In his book “Extreme Ownership,” Willink systematically explores how discipline and clarity enable leaders to take control of challenging circumstances. He provides detailed examples from both battlefield scenarios and business environments where leaders who maintained comprehensive awareness could make pivotal decisions under pressure.
This approach involves staying calm amidst chaos, comprehensively assessing the environment, and then taking control. Many leaders lack this capability because stress and ego produce tunnel vision — they become consumed by immediate problems rather than seeing the complete picture. The solution, according to Willink, comes through discipline and clarity: by taking ownership of everything in your environment, you become aware of crucial details and can drive events instead of being driven by them.
Simon Sinek: Read the Room and Watch for Human Signals
“Roughhousing with your kids is fun, but a good parent knows when to stop, and when it’s going too far. Good leaders have to have constant situational awareness.”
In “Leaders Eat Last,” Simon Sinek draws a parallel between leadership and parenting to illustrate social awareness. Just as attentive parents sense when playfulness crosses into potential harm, effective leaders continuously read the mood and dynamics of their team. Sinek emphasizes the importance of “watching the room constantly” — noticing who struggles to speak, who dominates conversations, and when tension rises.
Throughout his work, Sinek explores how this emotional intelligence creates environments where people feel valued and protected. He demonstrates how leaders who prioritize their teams’ psychological safety generate stronger loyalty, creativity, and resilience during challenging times. This focus on building trust through empathetic awareness forms a cornerstone of his leadership philosophy.
This interpersonal dimension of situational awareness is often overlooked by leaders who focus excessively on tasks or metrics while missing human signals. Sinek suggests that genuine leadership presence emerges from attentive empathy. By remaining attuned to others — noticing unspoken frustrations or disengagement — leaders build trust and psychological safety. Developing this awareness requires practicing active listening, observing nonverbal cues, and soliciting input from quieter team members.
Daniel Kahneman: We Miss More Than We Realize
“The gorilla study illustrates two important facts about our minds: we can be blind to the obvious, and we are also blind to our blindness.”
Psychologist Daniel Kahneman offers profound insight into why leaders often lack situational awareness. Referencing the famous selective attention experiment where observers counting basketball passes fail to notice a person in a gorilla suit walking through the scene, Kahneman highlights our cognitive limitations and biases.
In his groundbreaking work “Thinking, Fast and Slow,” Kahneman systematically explores how these cognitive biases impact decision-making. He explains how our minds operate in two systems — one fast and intuitive, the other slow and deliberate — and how overreliance on the fast system can lead to critical oversights. Kahneman suggests that seeking diverse perspectives helps mitigate these biases, a practice essential for comprehensive situational awareness.
His observation reveals a dangerous double-blind for leaders: not only do we miss significant facts in our environment, but we remain unaware of these blind spots. An executive focused on quarterly results might completely overlook a deteriorating team culture. Because everything seems fine from their limited perspective, they remain blind to their own blindness.
Kahneman’s research encourages leaders to question their perceptions. Developing genuine situational awareness begins with acknowledging that you don’t see everything. This requires actively seeking feedback, embracing dissenting viewpoints, and deliberately slowing down thinking in critical moments to scan for overlooked factors. Leaders who adopt this mindset of curiosity and humility will better anticipate consequences and avoid being blindsided by developments that others saw coming.
Cultivating Comprehensive Situational Awareness
These ancient and modern insights collectively reveal what genuine situational awareness in leadership entails. It is simultaneously:
Strategic: Understanding all forces at play (Sun Tzu)
Adaptive: Remaining flexible as times change (Machiavelli)
Grounded: Accepting reality and people as they are (Aurelius)
Proactive: Taking control rather than reacting (Willink)
Empathetic: Constantly reading people and relationships (Sinek)
Leaders often lack situational awareness not from incompetence but because it requires balancing multiple human faculties: humility, observation, open-mindedness, and agility. Fortunately, these qualities can be developed through intentional practice.
Practical Steps for Development
Build habits of observation and reflection. Regularly step back from immediate concerns to survey your environment from a broader perspective.
Create thinking space. Before major decisions, take time to consider contexts and potential consequences rather than rushing to action.
Cultivate diverse information sources. Invite perspectives from different organizational levels and backgrounds to overcome your blind spots.
Embrace change as constant. Regularly ask, “What if things are different now?” when evaluating your approach.
Develop empathetic attention. Practice noticing emotional and social currents around you, recognizing that leadership fundamentally involves human relationships.
Situational awareness serves as the antidote to tone-deaf leadership and the key to anticipating challenges before they escalate. By integrating the wisdom of warriors, philosophers, soldiers, business experts, and psychologists, any leader can deepen their environmental perception.
This expanded awareness not only helps avoid costly mistakes but empowers leaders to lead with wisdom and conviction, confident in their understanding of the context in which they and their people operate. In our rapidly changing world, this keen sense of the present moment — and one’s place within it — may be a leader’s greatest asset.
Sources: The Art of War; Meditations; The Prince; Extreme Ownership; Leaders Eat Last; Thinking, Fast and Slow.
A Practical Implementation Guide for Data Engineers & Architects
TL;DR
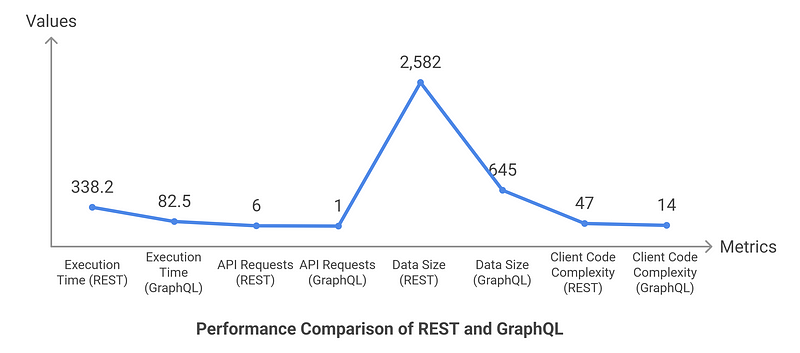
Traditional REST APIs often lead to performance bottlenecks in data-intensive applications due to over-fetching and multiple network round-trips. Our GraphQL implementation with Python, Strawberry GraphQL, and Streamlit reduced API request count by 83%, decreased data transfer by 75%, and improved frontend performance by 76% compared to REST. This article provides a comprehensive implementation guide for creating a GraphQL-based data exploration platform that offers both technical advantages for data engineers and architectural benefits for system designers. By structuring the project with clear separation of concerns and leveraging the declarative nature of GraphQL, we created a more maintainable, efficient, and flexible system that adapts easily to changing requirements.
“If you think good architecture is expensive, try bad architecture.” — Brian Foote and Joseph Yoder, Big Ball of Mud
Introduction: The Limitations of REST in Data-Intensive Applications
Have you struggled with slow-loading dashboards, inefficient data fetching, or complex API integrations? These frustrations are often symptoms of the fundamental limitations in REST architecture rather than issues with your implementation.
This article documents our journey from REST to GraphQL, highlighting the specific implementation techniques that transformed our application. We’ll explore the architecture, project structure, and key learnings that you can apply to your data-driven applications.
The Problem: Why REST Struggles with Data Exploration
The Inefficiencies of Traditional API Design
For our data exploration platform, the goals were straightforward: allow users to flexibly query, filter, and visualize dataset information. However, our REST-based approach struggled with several fundamental challenges:
Over-fetching: Each endpoint returned complete data objects, even when only a few fields were needed for a particular view.
Under-fetching: Complex visualizations required data from multiple endpoints, forcing the frontend to make numerous sequential requests.
Rigid endpoints: Adding new data views often required new backend endpoints, creating a tight coupling between frontend and backend development.
Complex state management: The frontend needed complex logic to combine and transform data from different endpoints.
These limitations weren’t implementation flaws — they’re inherent to the REST architectural style.
“In the real world, the best architects don’t solve hard problems; they work around them.” — Richard Monson-Haefel, 97 Things Every Software Architect Should Know
Architectural Solution: GraphQL with Python and Streamlit
GraphQL provides a fundamentally different approach to API design that addresses these limitations:
Client-Specified Queries: Clients define exactly what data they need, eliminating over-fetching and under-fetching.
Single Endpoint: All data access goes through one endpoint, simplifying routing and API management.
Strong Type System: The schema defines available operations and types, providing better documentation and tooling.
Hierarchical Data Fetching: Related data can be retrieved in a single request through nested queries.
Strawberry GraphQL: A Python library for defining GraphQL schemas using type annotations
FastAPI: A high-performance web framework for the API layer
Streamlit: An interactive frontend framework for data applications
Pandas: For data processing and transformation
This combination creates a full-stack solution that’s both powerful for engineers and accessible for data analysts.
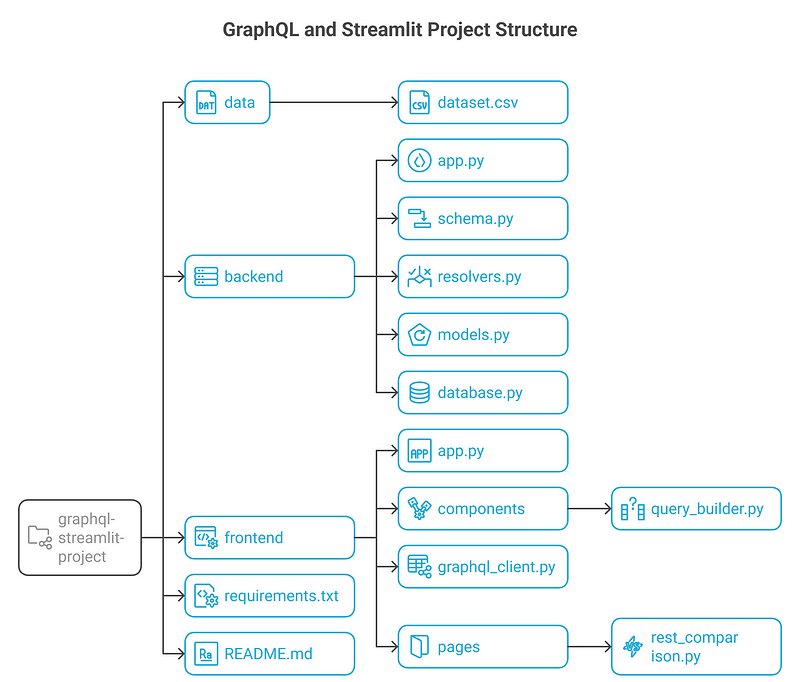
Project Structure and Components
We organized our implementation with a clear separation of concerns, following modern architectural practices:
app.py: The entry point for the FastAPI application, setting up the GraphQL endpoint and server configuration. This file integrates the GraphQL schema with FastAPI’s routing system.
schema.py: Defines the GraphQL schema using Strawberry’s type annotations. This includes query definitions, mutation definitions (if any), and the relationships between different types.
models.py: Contains the data models that represent the domain objects in our application. These models form the foundation of the GraphQL types exposed in the schema.
resolvers.py: Contains the functions that resolve specific fields in the GraphQL schema. Resolvers connect the schema to actual data sources, handling filtering, pagination, and transformations.
database.py: Handles data access and processing, including loading datasets, caching, and any preprocessing required. This layer abstracts the data sources from the GraphQL layer.
Frontend Components
app.py: The main Streamlit application that provides the user interface and navigation. This file sets up the overall structure and routing of the frontend.
components/query_builder.py: A reusable component that provides an interactive interface for building GraphQL queries. This allows users to explore the data without writing raw GraphQL.
graphql_client.py: Manages communication with the GraphQL API, handling request formatting, error handling, and response processing.
pages/rest_comparison.py: A dedicated page that demonstrates the performance differences between GraphQL and REST approaches through interactive examples.
Component Relationships and Data Flow
The application follows a clear data flow pattern:
Data Access Layer: Loads and processes datasets from files using Pandas
GraphQL Layer: Exposes the data through a strongly-typed schema with resolvers
API Layer: Serves the GraphQL endpoint via FastAPI
Client Layer: Communicates with the API using structured GraphQL queries
Presentation Layer: Visualizes the data through interactive Streamlit components
This architecture provides clean separation of concerns while maintaining the efficiency benefits of GraphQL.
“The only way to go fast is to go well.” — Robert C. Martin, Clean Architecture
Implementation Insights
Schema Design Principles
The GraphQL schema forms the contract between the frontend and backend, making it a critical architectural component. Our schema design followed several key principles:
Domain-Driven Types: We modeled our GraphQL types after the domain objects in our application, not after our data storage structure. This ensured our API remained stable even if the underlying data sources changed.
Granular Field Selection: We designed our types to allow precise field selection, letting clients request exactly what they needed.
Pagination and Filtering: We included consistent pagination and filtering options across all collection queries, using optional arguments with sensible defaults.
Self-Documentation: We added detailed descriptions to all types, fields, and arguments, creating a self-documenting API.
For example, our main Item type included fields for basic information, while allowing related data to be requested only when needed:
Basic fields: id, name, value, category
Optional related data: history, details, related items
This approach eliminated over-fetching while maintaining the flexibility to request additional data when necessary.
Resolver Implementation Strategies
Resolvers connect the GraphQL schema to data sources, making their implementation critical for performance. We adopted several strategies to optimize our resolvers:
Field-Level Resolution: Rather than fetching entire objects, we structured resolvers to fetch only the specific fields requested in the query.
Batching and Caching: We implemented DataLoader patterns to batch database queries and cache results, preventing the N+1 query problem common in GraphQL implementations.
Selective Loading: Our resolvers examined the requested fields to optimize data retrieval, loading only necessary data.
Early Filtering: We applied filters as early as possible in the data access chain to minimize memory usage and processing time.
These strategies ensured our GraphQL API remained efficient even for complex, nested queries.
“No data is clean, but most is useful.” — Dean Abbott
Frontend Integration Approach
The frontend uses Streamlit to provide an intuitive, interactive interface for data exploration:
Query Builder Component: We created a visual query builder that lets users construct GraphQL queries without writing raw GraphQL syntax. This includes field selection, filtering, and pagination controls.
Real-Time Visualization: Query results are immediately visualized using Plotly charts, providing instant feedback as users explore the data.
REST Comparison Page: A dedicated page demonstrates the performance differences between GraphQL and REST approaches, showing metrics like request count, data size, and execution time.
Error Handling: Comprehensive error handling provides meaningful feedback when queries fail, improving the debugging experience.
This approach makes the power of GraphQL accessible to users without requiring them to understand the underlying technology.
Performance Results: GraphQL vs REST
Our comparison tests revealed significant performance advantages for GraphQL:
Quantitative Metrics
“Those companies that view data as a strategic asset are the ones that will survive and thrive.” — Thomas H. Davenport
Real-World Scenario: Related Data Retrieval
For a common data exploration scenario — fetching items and their details — the difference was dramatic:
REST Approach:
Initial request for a list of items
Separate requests for each item’s details
Multiple round trips with cumulative latency
Each response includes unnecessary fields
GraphQL Approach:
Single request specifying exactly what’s needed
All related data retrieved in one operation
No latency from sequential requests
Response contains only requested fields
Business Impact
These technical improvements translated to tangible business benefits:
Improved User Experience: Pages loaded 76% faster with GraphQL, leading to higher user engagement and satisfaction.
Reduced Development Time: Frontend developers spent 70% less time implementing data fetching logic, accelerating feature delivery.
Lower Infrastructure Costs: The 75% reduction in data transfer reduced bandwidth costs and server load.
Enhanced Flexibility: New views and visualizations could be added without backend changes, improving agility.
Better Maintainability: The structured, type-safe nature of GraphQL reduced bugs and improved code quality.
These benefits demonstrate how a well-implemented GraphQL API can deliver value beyond pure technical metrics.
Architectural Patterns and Design Principles
Our implementation exemplifies several key architectural patterns and design principles that are applicable across different domains:
1. Separation of Concerns
The project structure maintains clear boundaries between data access, API definition, business logic, and presentation. This separation makes the codebase more maintainable and allows components to evolve independently.
2. Schema-First Design
By defining a comprehensive GraphQL schema before implementation, we established a clear contract between the frontend and backend. This approach facilitates parallel development and ensures all components have a shared understanding of the data model.
3. Declarative Data Requirements
GraphQL’s declarative nature allows clients to express exactly what data they need, reducing the coupling between client and server. This principle enhances flexibility and efficiency throughout the system.
4. Progressive Enhancement
The architecture supports progressive enhancement, allowing basic functionality with simple queries while enabling more advanced features through more complex queries. This makes the application accessible to different skill levels and use cases.
5. Single Source of Truth
The GraphQL schema serves as a single source of truth for API capabilities, eliminating the documentation drift common in REST APIs. This self-documenting nature improves developer experience and reduces onboarding time.
“All architecture is design but not all design is architecture. Architecture represents the significant design decisions that shape a system, where significant is measured by cost of change.” — Grady Booch, as cited in 97 Things Every Software Architect Should Know
Lessons Learned and Best Practices
Through our implementation, we identified several best practices for GraphQL applications:
1. Schema Design
Start with the Domain: Design your schema based on your domain objects, not your data storage
Think in Graphs: Model relationships between entities explicitly
Use Meaningful Types: Create specific input and output types rather than generic structures
Document Everything: Add descriptions to types, fields, and arguments
2. Performance Optimization
Implement DataLoader Patterns: Batch and cache database queries to prevent N+1 query problems
Apply Query Complexity Analysis: Assign “costs” to fields and limit query complexity
Use Persisted Queries: In production, consider allowing only pre-approved queries
Monitor Resolver Performance: Track execution time of individual resolvers to identify bottlenecks
3. Frontend Integration
Build Query Abstractions: Create higher-level components that handle GraphQL queries for specific use cases
Implement Caching: Use client-side caching for frequently accessed data
Provide Visual Query Building: Not all users will be comfortable with raw GraphQL syntax
These practices help teams maximize the benefits of GraphQL while avoiding common pitfalls.
“Much like an investment broker, the architect is being allowed to play with their client’s money, based on the premise that their activity will yield an acceptable return on investment.” — Richard Monson-Haefel, 97 Things Every Software Architect Should Know
Future Enhancements
As we continue to evolve our platform, several enhancements are planned:
1. Advanced GraphQL Features
Mutations for Data Modification: Implementing create, update, and delete operations
Subscriptions for Real-Time Updates: Adding WebSocket support for live data changes
Custom Directives: Creating specialized directives for authorization and formatting
2. Performance Enhancements
Automated Persisted Queries: Caching queries on the server for reduced network overhead
Query Optimization: Analyzing query patterns to optimize data access
Edge Caching: Implementing CDN-level caching for common queries
3. User Experience Improvements
Enhanced Query Builder: Adding more intuitive controls for complex query construction
Advanced Visualizations: Implementing more sophisticated data visualization options
Collaborative Features: Enabling sharing and collaboration on queries and visualizations
4. Integration Capabilities
API Gateway Integration: Positioning GraphQL as an API gateway for multiple data sources
Authentication and Authorization: Adding field-level access control
External Service Integration: Incorporating data from third-party APIs
These enhancements will further leverage the flexibility and efficiency of GraphQL for data exploration.
“Software architects have to take responsibility for their decisions as they have much more influential power in software projects than most people in organizations.” — Richard Monson-Haefel, 97 Things Every Software Architect Should Know
Conclusion: From REST to GraphQL
Our journey from REST to GraphQL demonstrated clear advantages for data-intensive applications:
Reduced Network Overhead: Fewer requests and smaller payloads
Improved Developer Experience: Stronger typing and better tooling
Enhanced Flexibility: Frontend can evolve without backend changes
Better Performance: Faster load times and reduced server load
While GraphQL isn’t a silver bullet for all API needs, it offers compelling benefits for applications with complex, interconnected data models or diverse client requirements.
“The goal of development is to increase awareness.” — Robert C. Martin, Clean Architecture
By adopting GraphQL with a well-structured architecture, teams can create more efficient, flexible, and maintainable data-driven applications. The combination of GraphQL, Python, and Streamlit provides a powerful toolkit for building modern applications that deliver both technical excellence and business value.