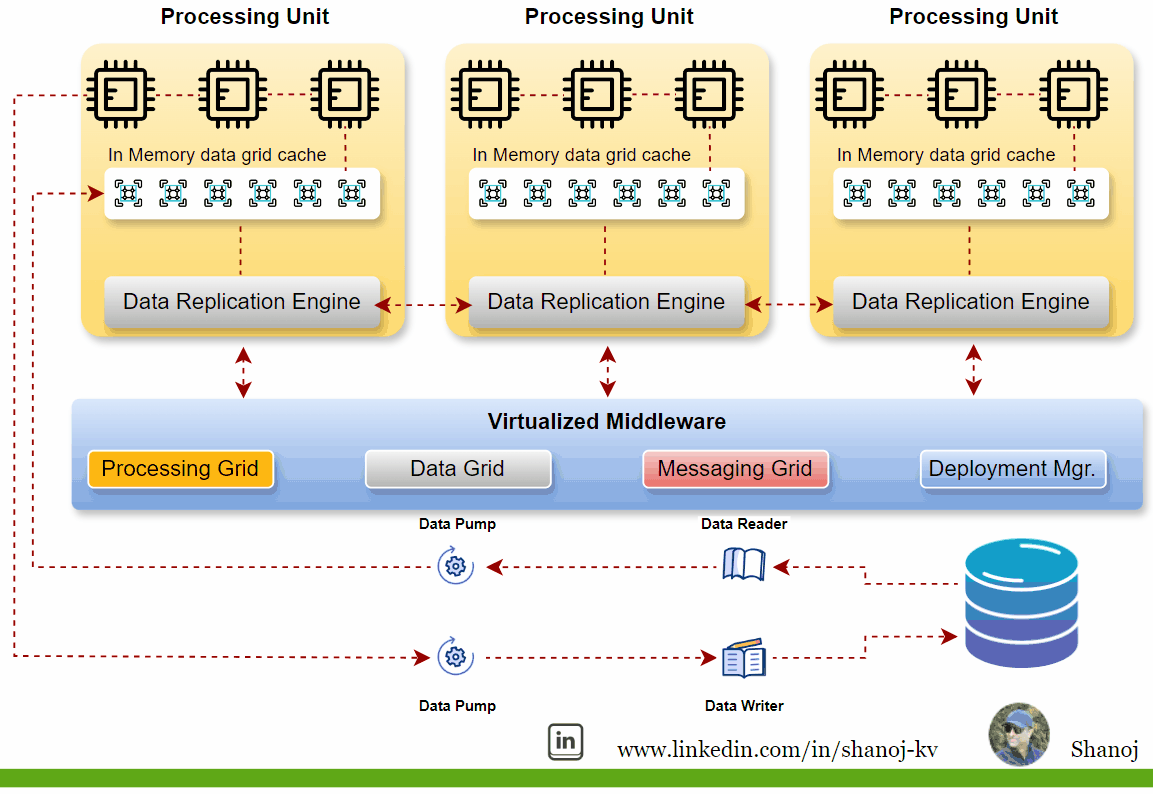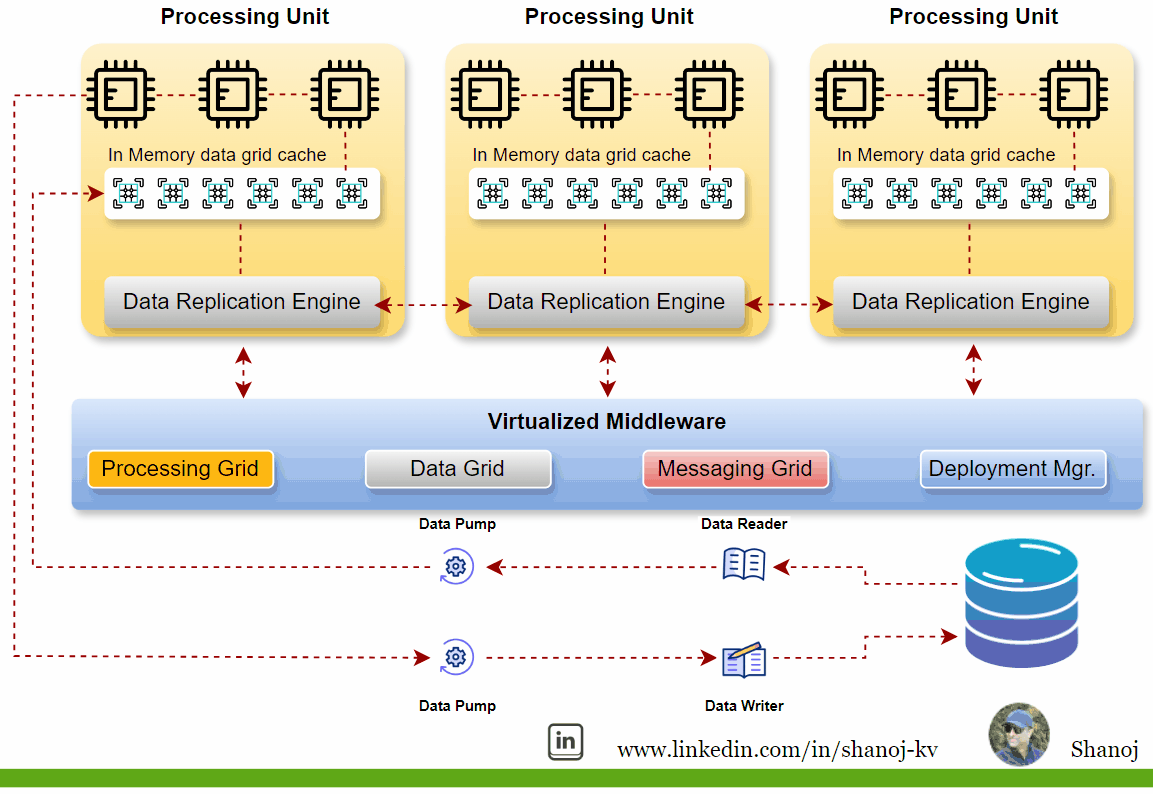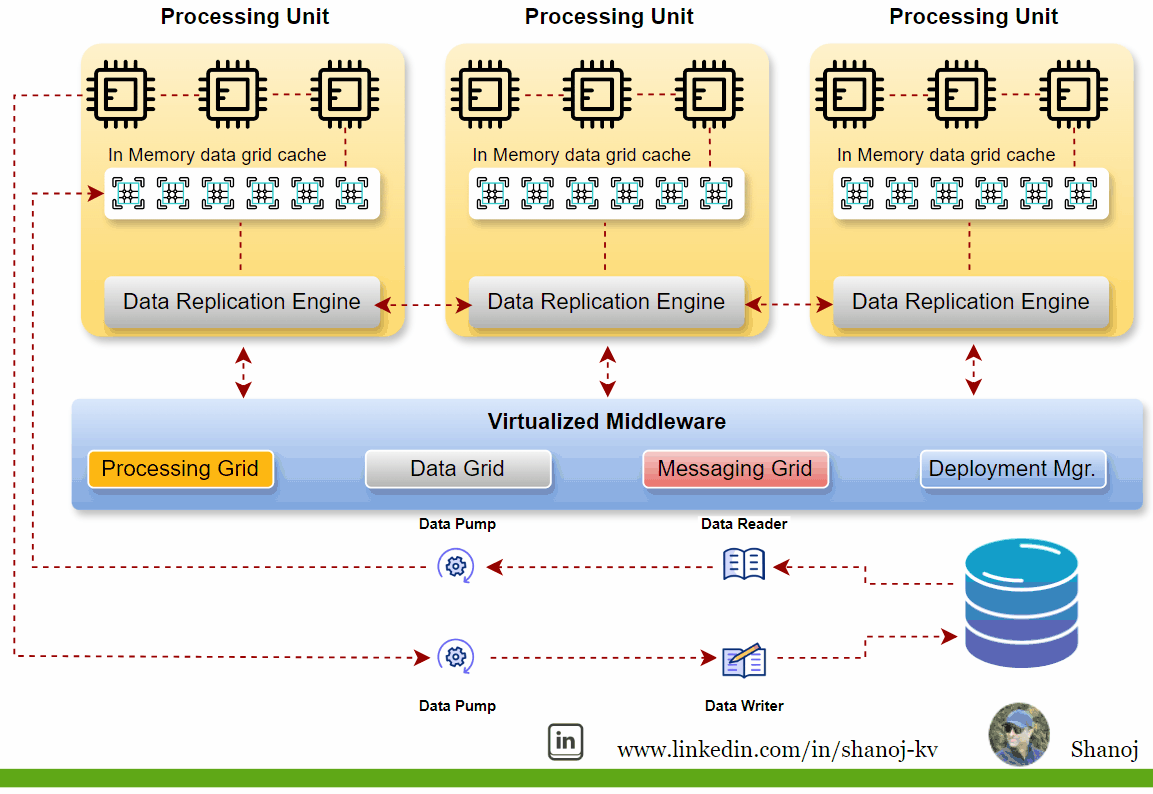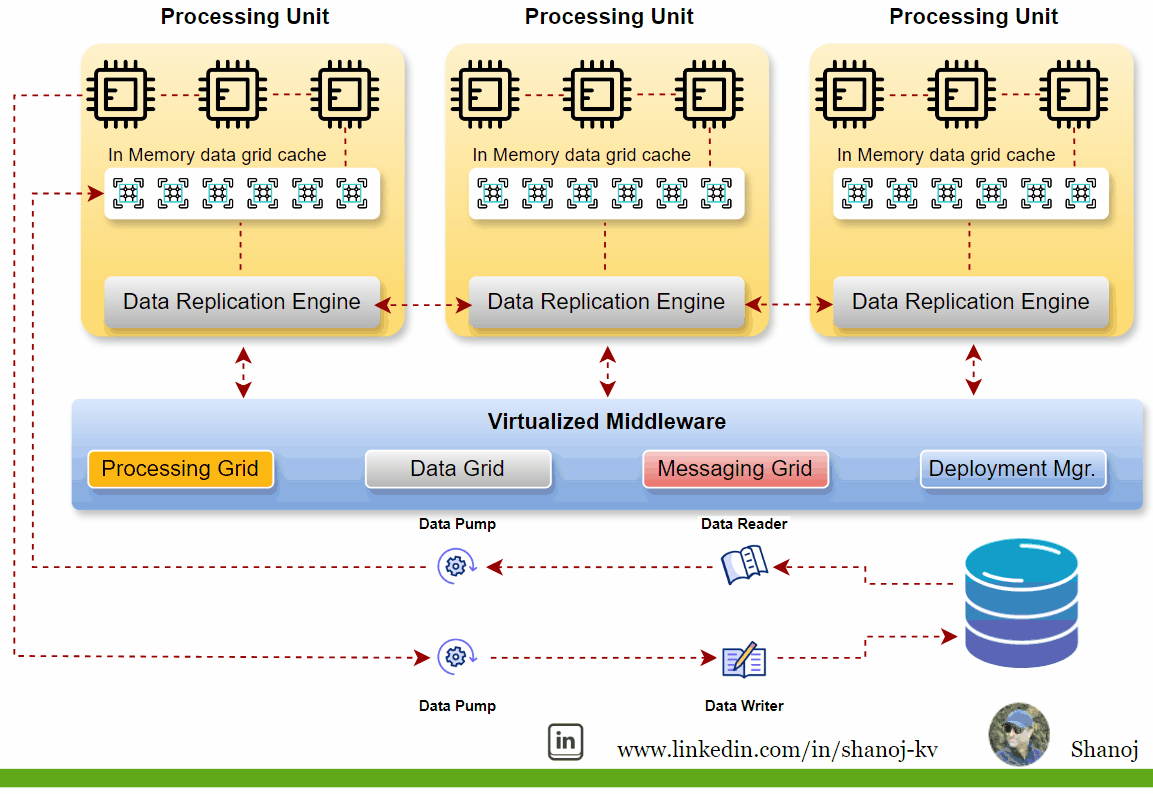
The Saga pattern is an architectural pattern utilized for managing distributed transactions in microservices architectures. It ensures data consistency across multiple services without relying on distributed transactions, which can be complex and inefficient in a microservices environment.
Key Concepts of the Saga Pattern

In the Saga pattern, a business process is broken down into a series of local transactions. Each local transaction updates the database and publishes an event or message to trigger the next transaction in the sequence. This approach helps maintain data consistency across services by ensuring that each step is completed before moving to the next one.
Types of Saga Patterns
There are several variations of the Saga pattern, each suited to different scenarios:
Choreography-based Saga: Each service listens for events and decides whether to proceed with the next step based on the events it receives. This decentralized approach is useful for loosely coupled services.
Orchestration-based Saga: A central coordinator, known as the orchestrator, manages the sequence of actions. This approach provides a higher level of control and is beneficial when precise coordination is required.
State-based Saga: Uses a shared state or state machine to track the progress of a transaction. Microservices update this state as they execute their actions, guiding subsequent steps.
Reverse Choreography Saga: An extension of the Choreography-based Saga where services explicitly communicate about how to compensate for failed actions.
Event-based Saga: Microservices react to events generated by changes in the system, performing necessary actions or compensations asynchronously.
Challenges Addressed by the Saga Pattern
The Saga pattern solves the problem of maintaining data consistency across multiple microservices in distributed transactions. It addresses several key challenges that arise in microservices architectures:
Distributed Transactions: In a microservices environment, a single business transaction often spans multiple services, each with its own database. Traditional ACID transactions don’t work well in this distributed context.
Data Consistency: Ensuring data consistency across different services and their databases is challenging when you can’t use a single, atomic transaction.
Scalability and Performance: Two-phase commit (2PC) protocols, which are often used for distributed transactions, can lead to performance issues and reduced scalability in microservices architectures.
Solutions Provided by the Saga Pattern
The Saga pattern solves these problems by:
- Breaking down distributed transactions into a sequence of local transactions, each handled by a single service.
- Using compensating transactions to undo changes if a step in the sequence fails, ensuring eventual consistency.
- Flexibility in transaction management, allowing services to be added, modified, or removed without significantly impacting the overall transactional flow.
- Better scalability by allowing each service to manage its own local transaction independently.
- Improving fault tolerance by providing mechanisms to handle and recover from failures in the transaction sequence.
- Visibility into the transaction process, which aids in debugging, auditing, and compliance.
Implementation Approaches
Choreography-Based Sagas

- Decentralized Control: Each service involved in the saga listens for events and reacts to them independently, without a central controller.
- Event-Driven Communication: Services communicate by publishing and subscribing to events.
- Autonomy and Flexibility: Services can be added, removed, or modified without significantly impacting the overall system.
- Scalability: Choreography can handle complex and frequent interactions more flexibly, making it suitable for highly scalable systems.
Orchestration-Based Sagas

- Centralized Control: A central orchestrator manages the sequence of transactions, directing each service on what to do and when.
- Command-Driven Communication: The orchestrator sends commands to services to perform specific actions.
- Visibility and Control: The orchestrator has a global view of the saga, making it easier to manage and troubleshoot.
Choosing Between Choreography and Orchestration
When to Use Choreography
- When you want to avoid creating a single point of failure.
- When services need to be highly autonomous and independent.
- When adding or removing services without disrupting the overall flow is a priority.
When to Use Orchestration
- When you need to guarantee a specific order of execution.
- When centralized control and visibility are crucial for managing complex workflows.
- When you need to manage the lifecycle of microservices execution centrally.
Hybrid Approach
In some cases, a combination of both approaches can be beneficial. Choreography can be used for parts of the saga that require high flexibility and autonomy, while orchestration can manage parts that need strict control and coordination.
Challenges and Considerations
- Complexity: Implementing SAGA can be more complex than traditional transactions.
- Lack of Isolation: Intermediate states are visible, which can lead to consistency issues.
- Error Handling: Designing and implementing compensating transactions can be tricky.
- Testing: Thorough testing of all possible scenarios is crucial but can be challenging.
The Saga pattern is powerful for managing distributed transactions in microservices architectures, offering a balance between consistency, scalability, and resilience. By carefully selecting the appropriate implementation approach, organizations can effectively address the challenges of distributed transactions and maintain data consistency across their services.
Stackademic 🎓
Thank you for reading until the end. Before you go:
- Please consider clapping and following the writer! 👏
- Follow us X | LinkedIn | YouTube | Discord
- Visit our other platforms: In Plain English | CoFeed | Differ
- More content at Stackademic.com