Author : Shanoj
is a Data engineer and solutions architect passionate about delivering business value and actionable insights through well-architected data products. He holds several certifications on AWS, Oracle, Apache, Google Cloud, Docker, Linux and focuses on data engineering and analysis using SQL, Python, BigData, RDBMS, Apache Spark, among other technologies.
He has 17+ years of history working with various technologies in the Retail and BFS domains.
System design interviews can be daunting due to their complexity and the vast knowledge required to excel. Whether you’re a recent graduate or a seasoned engineer, preparing for these interviews necessitates a well-thought-out strategy and access to the right resources. In this article, I’ll guide you to navigate the system design landscape and equip you to succeed in your upcoming interviews.
Start with the Basics
“Web Scalability for Startup Engineers” by Artur Ejsmont — This book is recommended as a starting point for beginners in system design.
“Designing Data-Intensive Applications” by Martin Kleppmann is described as a more in-depth resource for those with a basic understanding of system design.
It’s essential to establish a strong foundation before delving too deep into a subject. For beginners, “Web Scalability for Startup Engineers” is an excellent resource. It covers the basics and prepares you for more advanced concepts. After mastering the fundamentals, “Designing Data-Intensive Applications” by Martin Kleppmann will guide you further into data systems.
Microservices and Domain-Driven Design
“Building Microservices” by Sam Newman — Focuses on microservices architecture and its implications in system design.
Once you are familiar with the fundamentals, the next step is to explore the intricacies of the microservices architectural style through “Building Microservices.” To gain a deeper understanding of practical patterns and design principles, “Microservices Patterns and Best Practices” is an excellent resource. Lastly, for those who wish to understand the philosophy behind system architecture, “Domain-Driven Design” is a valuable read.
API Design and gRPC
“RESTful Web APIs” by Leonard Richardson, Mike Amundsen, and Sam Ruby provides a comprehensive guide to developing web-based APIs that adhere to the REST architectural style.
In the present world, APIs serve as the main connecting point of the internet. If you intend to design effective APIs, a good starting point would be to refer to “RESTful Web APIs” by Leonard Richardson and his colleagues. Moreover, if you are exploring the Remote Procedure Call (RPC) genre, particularly gRPC, then “gRPC: Up and Running” is a comprehensive guide.
Preparing for the Interview
“System Design Interview — An Insider’s Guide” by Alex Xu is an essential book for those preparing for challenging system design interviews.
It offers a comprehensive look at the strategies and thought processes required to navigate these complex discussions. Although it is one of many resources candidates will need, the book is tailored to equip them with the means to dissect and approach real interview questions. The book blends technical knowledge with the all-important communicative skills, preparing candidates to think on their feet and articulate clear and effective system design solutions. Xu’s guide demystifies the interview experience, providing a rich set of examples and insights to help candidates prepare for the interview process.
Domain-Specific Knowledge
Enhance your knowledge in your domain with books such as “Kafka: The Definitive Guide” for Distributed Messaging and “Cassandra: The Definitive Guide” for understanding wide-column stores. “Designing Event-Driven Systems” is crucial for grasping event sourcing and services using Kafka.
General Product Design
Pay attention to product design in system design. Books like “The Design of Everyday Things” and “Hooked: How to Build Habit-Forming Products” teach user-centric design principles, which are increasingly crucial in system design.
Online Resources
The internet is a goldmine of information. You can watch tech conference talks, follow YouTube channels such as Gaurav Sen’s System Design Interview and read engineering blogs from companies like Uber, Netflix, and LinkedIn.
System design is an iterative learning process that blends knowledge, curiosity, and experience. The resources provided here are a roadmap to guide you through this journey. With the help of these books and resources, along with practice and reflection, you will be well on your way to mastering system design interviews. Remember, it’s not just about understanding system design but also about thinking like a system designer.
Stackademic
Thank you for reading until the end. Before you go:
Please consider clapping and following the writer! 👏
As cloud computing continues to evolve, microservices architectures are becoming increasingly complex. To effectively manage this complexity, service meshes are being adopted. In this article, we will explain what a service mesh is, why it is necessary for modern cloud architectures, and how it addresses some of the most pressing challenges developers face today.
Understanding the Service Mesh
A service mesh is a configurable infrastructure layer built into an application that allows for the facilitation of flexible, reliable, and secure communications between individual service instances. Within a cloud-native environment, especially one that embraces containerization, a service mesh is critical in handling service-to-service communications, allowing for enhanced control, management, and security.
Why a Service Mesh?
As applications grow and evolve into distributed systems composed of many microservices, they often encounter challenges in service discovery, load balancing, failure recovery, security, and observability. A service mesh addresses these challenges by providing:
Dynamic Traffic Management: Adjusting the flow of requests and responses to accommodate changes in the infrastructure.
Improved Resiliency: Adding robustness to the system with patterns like retries, timeouts, and circuit breakers.
Enhanced Observability: Offering tools for monitoring, logging, and tracing to understand system performance and behaviour.
Security Enhancements: Ensuring secure communication through encryption and authentication protocols.
By implementing a service mesh, these distributed and loosely coupled applications can be managed more effectively, ensuring operational efficiency and security at scale.
Foundational Elements: Service Discovery and Proxies
The service mesh relies on two essential components — Consul and Envoy. The consul is responsible for service discovery, which means it keeps track of services, locations, and health status. It ensures that the system can adapt to changes in the environment. On the other hand, Envoy manages proxy services. It’s deployed alongside service instances and handles network communication. Envoy acts as an abstraction layer for traffic management and message routing.
Architectural Overview
The architecture consists of a Public and Private VPC setup, which encloses different clusters. The ‘LEFT_CLUSTER’ in the VPC is dedicated to critical services like logging and monitoring, which provide insights into the system’s operation and manage transactions. On the other hand, the ‘RIGHT_CLUSTER’ in the VPC contains services for Audit and compliance, Dashboards, and Archived Data, ensuring a robust approach to data management and regulatory compliance.
The diagram shows a service mesh architecture for sensitive banking operations in AWS. It comprises two clusters: the Left Cluster ( VPC) includes a Mesh Gateway, Bank Interface, Authentication and Authorization systems, and a Reconciliation Engine. Right Cluster (VPC) manages Audit, provides a Dashboard, stores Archived Data, and handles Notifications. Consul and Envoy Proxies efficiently manage communication. Monitored by dedicated tools, it ensures operational integrity and security in a complex banking ecosystem.
Mesh Gateways and Envoy Proxies
Mesh Gateways are crucial for inter-cluster communication, simplifying connectivity and network configurations. Envoy Proxies are strategically placed within the service mesh, managing the flow of traffic and enhancing the system’s ability to scale dynamically.
Security and User Interaction
The user’s journey begins with the authentication and authorization measures in place to verify and secure user access.
The Role of Consul
Consul’s service discovery capabilities are essential in allowing services like the Bank Interface and the Reconciliation Engine to discover each other and interact seamlessly, bypassing the limitations of static IP addresses.
Operational Efficiency
The service mesh’s contribution to operational efficiency is particularly evident in its integration with the Reconciliation Engine. This ensures that financial data requiring reconciliation is processed efficiently, securely, and directed towards the relevant services.
The Case for Service Mesh Integration
The shift to cloud-native architecture emphasizes the need for service meshes. This blueprint enhances agility, security, and technology, affirming the service mesh as pivotal for modern cloud networking.
In Plain English
Thank you for being a part of our community! Before you go:
Reverse ETL is the process of moving data from data warehouses or data lakes back to operational systems, applications, or other data sources. The term “reverse ETL” may seem confusing, as traditional ETL (Extract, Transform, Load) involves extracting data from source systems, transforming it for analytical purposes, and loading it into a data warehouse or data lake.
Traditional ETL
Traditional ETL vs. Reverse ETL
Traditional ETL involves:
Extracting data from operational source systems like databases, CRMs, and ERPs.
Transforming this data for analytics, making it cleaner and more structured.
Load the refined data into a data warehouse or lake for advanced analytical querying and reporting.
Unlike traditional ETL, where data is extracted from source systems, transformed, and loaded into a data warehouse, Reverse ETL operates differently. It begins with the transformed data already present in the data warehouse or data lake. From here, the process pushes this enhanced data back into various operational systems, SaaS applications, or other data sources. The primary goal of Reverse ETL is to leverage insights from the data warehouse to update or enhance these operational systems.
Why Reverse ETL?
A few key trends are driving the adoption of Reverse ETL:
Modern Data Warehouses: Platforms like Snowflake, BigQuery, and Redshift allow for easier data centralization.
Operational Analytics: Once data is centralized, and insights are gleaned, the next step is to operationalize those insights — pushing them back into apps and systems.
The SaaS Boom: The explosion of SaaS tools means data synchronization across applications is more critical than ever.
Applications of Reverse ETL
Reverse ETL isn’t just a fancy concept — it has practical applications that can transform business operations. Here are three valid use cases:
Customer Data Synchronization: Imagine an organization using multiple platforms like Salesforce (CRM), HubSpot (Marketing), and Zendesk (Support). Each platform gathers data in silos. With Reverse ETL, one can push a unified customer profile from a data warehouse to each platform, ensuring all departments have a consistent view of customers.
Operationalizing Machine Learning Models: E-commerce businesses often use ML models to predict trends like customer churn. With Reverse ETL, predictions made in a centralized data environment can be directly pushed to marketing tools. This enables targeted marketing efforts without manual data transfers.
Inventory and Supply Chain Management: For manufacturers, crucial data like inventory levels, sales forecasts, and sales data can be centralized in a data warehouse. Post analysis, this data can be pushed back to ERP systems using Reverse ETL, ensuring operational decisions are data-backed.
Challenges to Consider
Reverse ETL is undoubtedly valuable, but it poses certain challenges. The data refresh rate in a warehouse isn’t consistent, with some tables updating daily and others perhaps yearly. Additionally, some processes run sporadically, and there may be manual interventions in data management. Therefore, it’s essential to have a deep understanding of the source data’s characteristics and nature before starting a Reverse ETL journey.
Final Thoughts
Reverse ETL methodology has been used for some time, but it has only recently gained formal recognition. The increasing popularity of specialized Reverse ETL tools such as Census, Hightouch, and Grouparoo demonstrates its growing significance. When implemented correctly, it can significantly improve operations and provide valuable data insights. This makes it a game-changer for businesses looking to streamline their processes and gain deeper insights from their data.
Stay tuned and follow mefor more updates. Don’t forget to give your 👏 if you enjoy reading the article to support your author.
Stackademic
Thank you for reading until the end. Before you go:
Please consider clapping and following the writer! 👏
Apache Spark, one of the most powerful distributed data processing engines., provides multiple ways to handle corrupted records during the read process. These methods, known as read modes, allow users to decide how to address malformed data. This article will delve into these read modes, providing a comprehensive understanding of their functionalities and use cases.
Permissive Mode (default):
Spark adopts a lenient approach to data discrepancies in the permissive mode, which is the default setting.
Handling of Corrupted Records: Spark will set all fields to null for that specific record upon encountering a corrupted record. Moreover, the corrupted records get allocated to a column named. _corrupt_record.
Advantage: This ensures that Spark continues processing without interruption, even if it comes across a few corrupted records. It’s a forgiving mode, handy when data integrity is not the sole priority, and there’s an emphasis on ensuring continuity in processing.
DropMalformed Mode:
As the title suggests, this mode is less forgiving than permissive. Spark takes stringent action against records that don’t match the schema.
Handling of Corrupted Records: Spark directly drops rows that contain corrupted or malformed records, ensuring only clean records remain.
Advantage: This mode is instrumental if the objective is to work solely with records that align with the expected schema, even if it means discarding a few anomalies. If you aim for a clean dataset and are okay with potential data loss, this mode is your go-to.
FailFast Mode:
FailFast mode is the strictest among the three and is for scenarios where data integrity cannot be compromised.
Handling of Corrupted Records: Spark immediately halts the job in this mode and throws an exception when it spots a corrupted record.
Advantage: This strict approach ensures unparalleled data quality. This mode is ideal if the dataset must strictly adhere to the expected schema without discrepancies.
To cement the understanding of these read modes, let’s delve into a hands-on example:
from pyspark.sql import SparkSession import getpass
# Permissive Mode print("Permissive Mode:") print("Expected: Rows with malformed 'age' values will have null in the 'age' column.") dfPermissive = spark.read.schema(expected_schema).option("mode", "permissive").json("sample_data_malformed.json") dfPermissive.show()
# DropMalformed Mode print("\nDropMalformed Mode:") print("Expected: Rows with malformed 'age' values will be dropped.") dfDropMalformed = spark.read.schema(expected_schema).option("mode", "dropMalformed").json("sample_data_malformed.json") dfDropMalformed.show()
The discussion about read modes (Permissive, DropMalformed, and FailFast) pertains primarily to DataFrames and Datasets when sourcing data from formats like JSON, CSV, Parquet, and more. These modes become critical when there’s a risk of records not aligning with the expected schema.
Resilient Distributed Datasets (RDDs), a foundational element in Spark, represent a distributed set of objects. Unlike DataFrames and Datasets, RDDs don’t possess a schema. Consequently, when working with RDDs, it’s more about manually processing data than relying on predefined structures. Hence, RDDs don’t intrinsically incorporate these read modes. However, these modes become relevant when transitioning data between RDDs and DataFrames/Datasets or imposing a schema on RDDs.
Understanding and choosing the appropriate read mode in Spark can significantly influence data processing outcomes. While some scenarios require strict adherence to data integrity, others prioritize continuity in processing. By providing these read modes, Spark ensures that it caters to a diverse range of data processing needs. The mode choice should always align with the overarching project goals and data requirements.
Stackademic
Thank you for reading until the end. Before you go:
Please consider clapping and following the writer! 👏
In this article, I talk about how to build a system like Twitter. I focus on the problems that come up when very famous people, like Elon Musk, tweet and many people see it at once. I’ll share the basic steps, common issues, and how to keep everything running smoothly. My goal is to give you a simple guide on how to make and run such a system.
System Requirements
Functional Requirements:
User Management: Includes registration, login, and profile management.
Tweeting: Enables users to broadcast short messages.
Retweeting: This lets users share others’ content.
Timeline: Showcases tweets from the user and those they follow.
Non-functional Requirements:
Scalability: Must accommodate millions of users.
Availability: High uptime is the goal, achieved through multi-regional deployments.
Latency: Prioritizes real-time data retrieval and instantaneous content updates.
Security: Ensures protection against unauthorized breaches and data attacks.
Architecture Overview
This diagram outlines a microservices-based social media platform design. The user’s request flows through a CDN, then a load balancer to distribute the load among web servers. Core services and data storage solutions like DynamoDB, Blob Storage, and Amazon RDS are defined. An intermediary cache ensures fast data retrieval, and the Amazon Elasticsearch Service provides advanced search capabilities. Asynchronous tasks are managed through SQS, and specialized services for trending topics, direct messaging, and DDoS mitigation are included for a holistic approach to user experience and security.
Scalability
Load Balancer: Directs traffic to multiple servers to balance the load.
Microservices: Functional divisions ensure scalability without interference.
Auto Scaling: Adjusts resources based on the current demand.
Data Replication: Databases like DynamoDB replicate data across different locations.
CDN: Content Delivery Networks ensure swift asset delivery, minimizing latency.
Security
Authentication: OAuth 2.0 for stringent user validation.
Authorization: Role-Based Access Control (RBAC) defines user permissions.
Encryption: SSL/TLS for data during transit; AWS KMS for data at rest.
DDoS Protection: AWS Shield protects against volumetric attacks.
Data Design (NoSQL, e.g., DynamoDB)
User Table
Tweets Table
Timeline Table
Multimedia Content Storage (Blob Storage)
In the multimedia age, platforms akin to Twitter necessitate a system adept at managing images, GIFs, and videos. Blob storage, tailored for unstructured data, is ideal for efficiently storing and retrieving multimedia content, ensuring scalable, secure, and prompt access.
Backup Databases
In the dynamic world of microblogging, maintaining data integrity is imperative. Backup databases offer redundant data copies, shielding against losses from hardware mishaps, software anomalies, or malicious intents. Strategically positioned backup databases bolster quick recovery, promoting high availability.
Queue Service
The real-time interaction essence of platforms like Twitter underscores the importance of the Queue Service. This service is indispensable when managing asynchronous tasks and coping with sudden traffic influxes, especially with high-profile tweets. This queuing system:
Handles requests in an orderly fashion, preventing server inundations.
Decouples system components, safeguarding against cascading failures.
Preserves system responsiveness during high-traffic episodes.
Workflow Design
Standard Workflow
Tweeting: User submits a tweet → Handled by the Tweet Microservice → Authentication & Authorization → Stored in the database → Updated on the user’s timeline and followers’ timelines.
Retweeting: User shares another’s tweet → Retweet Microservice handles the action → Authentication & Authorization → The retweet is stored and updated on timelines.
Timeline Management: A user’s timeline combines tweets, retweets, and tweets from users they follow. Caching mechanisms like Redis can enhance timeline retrieval speed for frequently accessed ones.
Enhanced Workflow Design
Tweeting by High-Profile Users (high retrieval rate):
Tweet Submission: Elon Musk (or any high-profile user) submits a tweet.
Tweet Microservice Handling: The tweet is directed to the Tweet Microservice via the Load Balancer. Authentication and Authorization checks are executed.
Database Update: Once approved, the tweet is stored in the Tweets Table.
Deferred Update for Followers: High-profile tweets can be efficiently disseminated without overloading the system using a publish/subscribe (Pub/Sub) mechanism.
Caching: Popular tweets, due to their high retrieval rate, benefit from caching mechanisms and CDN deployments.
Notifications: A selective notification system prioritizes active or frequent interaction followers for immediate notifications.
Monitoring and Auto-scaling: Resources are adjusted based on real-time monitoring to handle activity surges post high-profile tweets.
Advanced Features and Considerations
Though the bedrock components of a Twitter-esque system are pivotal, integrating advanced features can significantly boost user experience and overall performance.
Trending Topics and Analytics
A hallmark of platforms like Twitter is real-time trend spotting. An ever-watchful service can analyze tweets for patterns, hashtags, or mentions, displaying live trends. Combined with analytics, this offers insights into user patterns and preferences, peak tweeting times, and favoured content.
Direct Messaging
Given the inherently public nature of tweets, a direct messaging system serves as a private communication channel. This feature necessitates additional storage, retrieval mechanisms, and advanced encryption measures to preserve the sanctity of private interactions.
Push Notifications
To foster user engagement, real-time push notifications can be implemented. These alerts can inform users about new tweets, direct messages, mentions, or other salient account activities, ensuring the user stays connected and engaged.
Search Functionality
With the exponential growth in tweets and users, a sophisticated search mechanism becomes indispensable. An advanced search service, backed by technologies like ElasticSearch, can render the task of content discovery effortless and precise.
Monetization Strategies
Integrating monetisation mechanisms is paramount to ensure the platform’s sustainability and profitability. This includes display advertisements, promoted tweets, business collaborations, and more. However, striking a balance is crucial, ensuring these monetization strategies don’t intrude on the user experience.
To make a site like Twitter, you need a good system, strong safety, and features people like. Basic things like balancing traffic, organizing data, and keeping it safe are a must. But what really makes a site stand out are the new and advanced features. By thinking carefully about all these things, you can build a site that’s big and safe, but also fun and easy for people to use.
If you enjoyed reading this and would like to explore similar content, please refer to the following link:
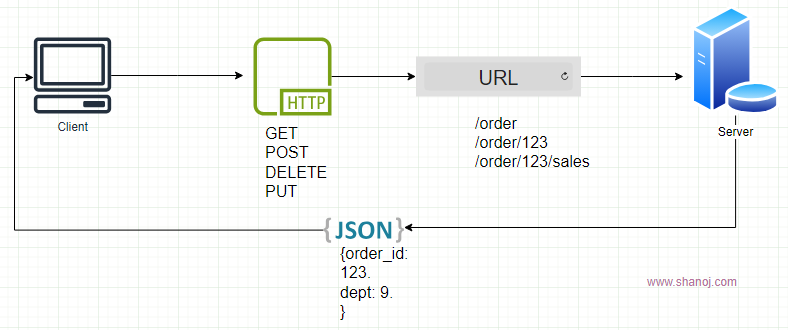
API, short for Application Programming Interface, is a fundamental concept in software development. It establishes well-defined methods for communication between software components, enabling seamless interaction. APIs define how software components communicate effectively.
Key Concepts in APIs:
Interface vs. Implementation: An API defines an interface through which one software piece can interact with another, just like a user interface allows users to interact with software.
APIs are for Software Components: APIs primarily enable communication between software components or applications, providing a standardized way to send and receive data.
API Address: An API often has an address or URL to identify its location, which is crucial for other software to locate and communicate with it. In web APIs, this address is typically a URL.
Exposing an API: When a software component makes its API available, it “exposes” the API. Exposed APIs allow other software components to interact by sending requests and receiving responses.
Different Types of APIs:
Let’s explore the four main types of APIs: Operating System API, Library API, Remote API, and Web API.
Operating System API
An Operating System API enables applications to interact with the underlying operating system. It allows applications to access essential OS services and functionalities.
Use Cases:
File Access:Applications often require file system access for reading, writing, or managing files. The Operating System API facilitates this interaction.
Network Communication:To establish network connections for data exchange, applications rely on the OS’s network-related services.
User Interface Elements:Interaction with user interface elements like windows, buttons, and dialogues is possible through the Operating System API.
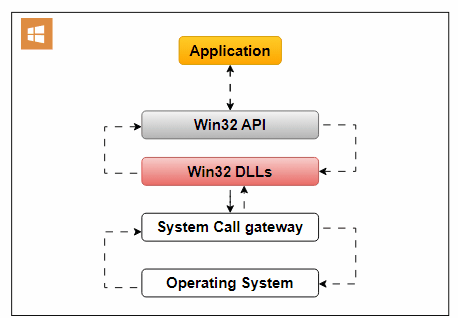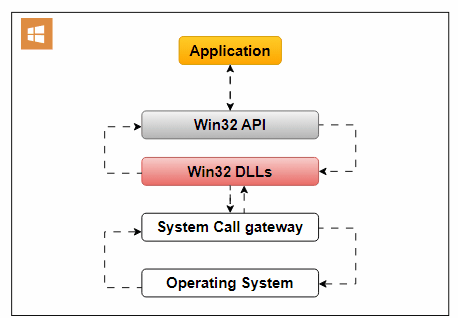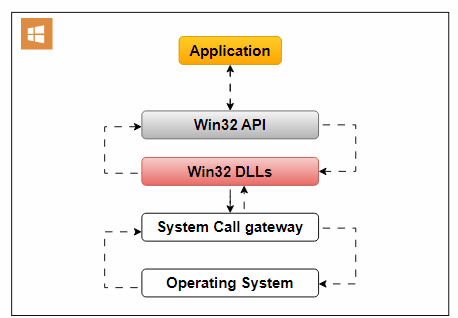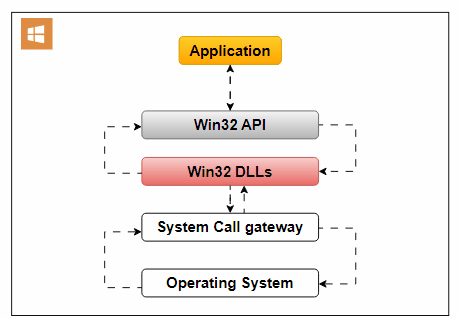
An example of an Operating System API is the Win32 API, designed for Windows applications. It offers functions for handling user interfaces, file operations, and system settings.
Library API
Library APIs allow applications to utilize external libraries or modules simultaneously. These libraries provide additional functionalities, enhancing applications.
Use Cases:
Extending Functionality: Applications often require specialized functionalities beyond their core logic. Library APIs enable the inclusion of these functionalities.
Code Reusability:Developers can reuse pre-built code components by using libraries, saving time and effort.
Modularity: Library APIs promote modularity in software development by separating core functionality from auxiliary features.
For example, an application with a User library may incorporate logging capabilities through a Logging library’s API.
Remote API
Remote APIs enable communication between software components or applications distributed over a network. These components may not run in the same process or server.
Key Features:
Network Communication: Remote APIs facilitate communication between software components on different machines or servers.
Remote Proxy:One component creates a proxy (often called a Remote Proxy) to communicate with the remote component. This proxy handles network protocols, addressing, method signatures, and authentication.
Platform Consistency: Client and server components using a Remote API must often be developed using the same platform or technology stack.
Examples of Remote APIs include DCOM, .NET Remoting, and Java RMI (Remote Method Invocation).
Web API
Web APIs allow web applications to communicate over the Internet based on standard protocols, making them interoperable across platforms, OSs, and programming languages.
Key Features:
Internet Communication: Web APIs enable web apps to interact with remote web services and exchange data over the Internet.
Platform-Agnostic: Web APIs support web apps developed using various technologies, promoting seamless interaction.
Widespread Popularity: Web APIs are vital in modern web development and integration.
Use Cases:
Data Retrieval: Web apps can access Web APIs to retrieve data from remote services, such as weather information or stock prices.
Action Execution: Web APIs allow web apps to perform actions on remote services, like posting a tweet on Twitter or updating a user’s profile on social media.
Types of Web APIs
Now, let’s explore four popular approaches for building Web APIs: SOAP, REST, GraphQL, and gRPC.
SOAP (Simple Object Access Protocol): Is a protocol for exchanging structured information to implement web services, relying on XML as its message format. Known for strict standards and reliability, it is suitable for enterprise-level applications requiring ACID-compliant transactions.
REST (Representational State Transfer): This architectural style uses URLs and data formats like JSON and XML for message exchange. It is simple, stateless, and widely used in web and mobile applications, emphasizing simplicity and scalability.
GraphQL: Developed by Facebook, GraphQL provides flexibility in querying and updating data. Clients can specify the fields they want to retrieve, reducing over-fetching and enabling real-time updates.
gRPC (Google Remote Procedure Call): Developed by Google, gRPC is based on HTTP/2 and Protocol Buffers (protobuf). It excels in microservices architectures and scenarios involving streaming or bidirectional communication.
Real-World Use Cases:
Operating System API: An image editing software accesses the file system for image manipulation.
Library API: A web application leverages the ‘TensorFlow’ library API to integrate advanced machine learning capabilities for sentiment analysis of user-generated content.
Remote API: A ride-sharing service connects distributed passenger and driver apps.
Web API: An e-commerce site provides real-time stock availability information.
SOAP: A banking app that handles secure financial transactions.
REST: A social media platform exposes a RESTful API for third-party developers.
GraphQL: A news content management system that enables flexible article queries.
gRPC: An online gaming platform that maintains real-time player-server communication.
APIs are vital for effective software development, enabling various types of communication between software components. The choice of API type depends on specific project requirements and use cases. Understanding these different API types empowers developers to choose the right tool for the job.
If you enjoyed reading this and would like to explore similar content, please refer to the following link:
Column selection is a frequently used operation when working with Spark DataFrames. Spark provides two built-in methods select() and selectExpr(), to facilitate this task. In this article, we will discuss how to use both methods, explain their main differences, and provide guidance on when to choose one over the other.
To demonstrate these methods, let’s start by creating a sample DataFrame that we will use throughout this article:
# Import the necessary libraries from pyspark.sql import SparkSession from pyspark.sql.types import StructType, StructField, IntegerType, StringType
# Create the DataFrame df = spark.createDataFrame(data, schema=schema)
# Show the DataFrame df.show()
DataFrames: In Spark, a DataFrame is a distributed collection of data organized into named columns, similar to a table in a relational database. DataFrames offer a structured and efficient way to work with structured and semi-structured data.
Understanding select()
The select() method in PySpark’s DataFrame API is used to project-specific columns from a DataFrame. It accepts various arguments, including column names, Column objects, and expressions.
List of Column Names: You can pass column names as a list of strings to select specific columns.
List of Column Objects: Alternatively, you can import the Spark Column class from pyspark.sql.functions, create column objects, and pass them in a list.
Expressions: It allows you to create new columns based on existing ones by providing expressions. These expressions can include mathematical operations, aggregations, or any valid transformations.
“*” (Star): The star syntax selects all columns, akin to SELECT * in SQL.
Select Specific Columns
To select a subset of columns, provide their names as arguments to the select() method:
selectExpr()
The pyspark.sql.DataFrame.selectExpr() method is similar to select(), but it accepts SQL expressions in string format. This lets you perform more complex column selection and transformations directly within the method. Unlike select(), selectExpr()It only accepts strings as input.
SQL-Like Expressions
One of the key advantages of selectExpr() is its ability to work with SQL-like expressions for column selection and transformation. For example, you can calculate the length of the ‘first_name’ column and alias it as ‘name_length’ as follows:
Built-In Hive Functions
selectExpr() also allows you to leverage built-in Hive functions for more advanced transformations. This is particularly useful for users familiar with SQL or Hive who want to write concise and expressive code. For example, you can cast the ‘age’ column from string to integer:
Adding Constants
You can also add constant fields to your DataFrame using selectExpr(). For example, you can add the current date as a new column:
selectExpr() is a powerful method for column selection and transformation when you need to perform more complex operations within a single method call.
Key Differences and Best Use Cases
Now that we have explored both select() and selectExpr() methods, let’s summarize their key differences and identify the best use cases for each.
select() Method:
Use select() when you need to select specific columns or create new columns using expressions.
It’s suitable for straightforward column selection and basic transformations.
Provides flexibility with column selection using lists of column names or objects.
Use it when applying custom functions or complex operations on columns.
selectExpr() Method:
Choose selectExpr() when you want to leverage SQL-like expressions for column selection and transformations.
It’s ideal for users familiar with SQL or Hive who want to write concise, expressive code.
Supports compatibility with built-in Hive functions, casting data types, and adding constants.
Use it when you need advanced SQL-like capabilities for selecting and transforming columns.
In this article, I want to clarify that my intent is not to show bias towards or against any country or perspective. Instead, I aim to offer my observations and insights into my motherland, India, from the lens of an investor who is perpetually seeking better avenues for investment and is committed to being a part of the ever-evolving global economy.
As of the end of 2023, India is poised for explosive economic growth in the coming decade, potentially becoming the world’s third-largest economy by 2027, surpassing both Japan and Germany. This article will explore the factors driving India’s remarkable growth story, the investment opportunities it presents, and how you can potentially benefit as an investor.
The Growth Factors:
Global Offshoring: India’s outsourcing industry has long been a leader in software development and customer service. With a vast pool of talented engineers and a young workforce, India is the go-to destination for companies seeking cost-effective and skilled labour. In addition to traditional outsourcing, India is also attracting investment in manufacturing, contributing to the country’s economic growth.
Financial Transformation: India has embarked on a journey of financial transformation, marked by initiatives like Aadhar, a biometric authentication system, and India Stack, a decentralized utility for payments. These innovations have made it easier for people and businesses to access services, apply for credit, and conduct transactions more efficiently. This transformation is fostering financial inclusion and driving economic growth.
Energy Transition: India is making substantial strides in transitioning from fossil fuels to renewable energy sources. With a commitment to renewable energy, the country is attracting investments and fostering innovation in the sector. This transition addresses environmental concerns and contributes to economic growth and energy security.
Demographic Advantage: India’s demographic advantage cannot be overstated. The country is home to over 600 million people aged between 18 and 35, with 65% under 35. This youthful workforce provides a significant competitive edge in the global labour market and contributes to India’s economic growth. It’s projected that India’s demographic dividend will persist until 2055–56 and peak around 2041 when the share of the working-age population — 20–59 years — is expected to hit 59%.
Chandrayaan-3, a Historic Achievement: India has achieved remarkable success in space exploration with its Chandrayaan missions. Chandrayaan-3 is the third mission in the Chandrayaan program, a series of lunar exploration missions developed by the Indian Space Research Organisation (ISRO). Launched on 14 July 2023, this mission consists of a lunar lander named Vikram and a lunar rover named Pragyan, similar to those launched aboard Chandrayaan-2 in 2019.
Chandrayaan-3 made history by successfully landing near the Moon’s south pole on 23 August at 18:03 IST (12:33 UTC). This achievement marked India as the fourth country to land on the Moon successfully and the first to do so near the lunar south pole, a region of great scientific interest.
Unified Payments Interface (UPI), a Technological Revolution: Amid India’s remarkable economic growth, technology has transformed the country’s financial landscape. One standout innovation is the Unified Payments Interface (UPI). UPI is a real-time payment system that facilitates effortless and instantaneous money transfers between bank accounts, all through a mobile device, and with no associated fees.
Introduced by the National Payments Corporation of India (NPCI) in 2016, UPI has rapidly gained widespread adoption, fundamentally altering how Indians engage in financial transactions. An impressive 300 million UPI users and 500 million merchants actively utilize this platform to facilitate business transactions.
With UPI, users can seamlessly transfer funds to one another using a unique UPI ID or a Virtual Payment Address (VPA). This revolutionary technology has simplified and democratized financial transactions, making them accessible and efficient for millions of individuals.
The most significant impact of UPI has been its influence on transaction methods in India. According to research by GlobalData, cash transactions, once constituting 90% of the total volume, have now dwindled to less than 60%, with UPI and other digital transaction systems claiming the lion’s share of the remaining space.
National Logistics Policy (NLP) is a transformative initiative by the Indian government that seeks to revolutionize the country’s logistics sector. India has long grappled with high logistics costs, inefficiencies, and delays in transporting goods. This policy addresses these issues by introducing a hub-and-spoke model, where goods are consolidated at central hubs before being distributed to various destinations. By optimizing transportation routes, enhancing digitalization, and simplifying regulatory procedures, the policy can significantly reduce logistics costs, boost the efficiency of goods movement, and make India more competitive globally.
Much like the Unified Payments Interface (UPI) revolutionized digital payments, the National Logistics Policy could usher in a new era of efficiency and growth in the logistics sector, benefiting businesses and consumers alike.
India’s Expanding Road Network: India’s remarkable achievement in becoming the second-largest country globally regarding road network size, trailing only the United States, presents a compelling case for investors. With an impressive addition of 1.45 lakh kilometres to its road connectivity over the past eight years, India’s commitment to infrastructure development is evident. Minister for Road Transport and Highways, Nitin Gadkari, has been instrumental in driving this progress, focusing on improving highways and establishing greenfield expressways. Investors should take note of the near completion of the Delhi-Mumbai Expressway, India’s longest infrastructure project, showcasing the country’s dedication to modernizing its transportation networks.
Under Gadkari’s (Minister for Road Transport and Highways) leadership, the National Highways Authority of India (NHAI) added 30,000 km to India’s 91,287 km road network. Toll revenue surged from Rs 4,770 crore to Rs 41,352 crore in nine years, promising investment growth. With a target of Rs 71.30 lakh crore revenue, India beckons investors to its modernized transportation and logistics sectors, exemplified by efficient FASTag implementation.
Investment Opportunities:
While India’s rapid economic growth presents enticing investment opportunities, it’s essential to approach them wisely. Here are key promises that India holds for investors:
Vast Market Potential: India is home to over 1.3 billion people, making it one of the largest consumer markets in the world. This presents a significant opportunity for businesses to tap into a massive customer base.
Skilled Workforce: India possesses a pool of highly skilled and educated professionals, particularly in technology, engineering, and finance. This talent pool is attractive to global companies looking to expand their operations.
Government Initiatives: The Indian government has introduced various initiatives to promote foreign investment, such as “Make in India” and “Digital India.” These programs aim to ease the business environment and encourage investment in critical sectors.
Infrastructure Development: India invests in infrastructure development, including transportation, logistics, and smart cities. These projects open avenues for private investment and offer potential returns.
Startup Ecosystem: India’s startup ecosystem is thriving, with numerous successful startups in sectors like e-commerce, fintech, and healthcare. Investors can explore opportunities in this dynamic sector.
Comparing India to the U.S. Stock Market:
When considering investing in India’s growth, it’s crucial to acknowledge that economic growth (GDP) doesn’t always directly correlate with stock market performance. For instance, the stock market has often outperformed GDP growth in the United States. While India’s GDP growth is projected to be remarkable, it doesn’t guarantee stock market success.
Over the years, the U.S. stock market has demonstrated robust performance, with average annual returns between 7% and 9%. This consistency and predictability make it a preferred choice for many investors.
India’s economic growth story is undeniably compelling, with immense potential for investors. However, the complexity of global markets and the multitude of factors influencing stock performance necessitate a careful and diversified approach to investments. Evaluating your risk tolerance, diversifying your portfolio, and consulting with a financial advisor who can provide tailored guidance are essential as you contemplate your investment strategy.
Whether you choose to invest directly in Indian stocks, explore ETFs, or stick to the familiar U.S. stock market, staying informed and staying the course is key to making sound investment decisions.
I recently asked my close friends for feedback on what skills I should work on to advance my career. The consensus was clear: I must focus on AI/ML and front-end technologies. I take their suggestions seriously and have decided to start with a strong foundation. Since I’m particularly interested in machine learning, I realized that mathematics is at the core of this field. Before diving into the technological aspects, I must strengthen my mathematical fundamentals. With this goal in mind, I began exploring resources and found “Essential Math for Data Science” by Thomas Nield to be a standout book. In this review, I’ll provide my honest assessment of the book.
Review:
Chapter 1: Basic Mathematics and Calculus The book starts with an introduction to basic mathematics and calculus. This chapter serves as a refresher for those new to mathematical concepts. It covers topics like limits and derivatives, making it accessible for beginners while providing a valuable review for others. The use of coding exercises helps reinforce understanding.
Chapter 2: Probability The second chapter introduces probability with relevant real-life examples. This approach makes the abstract concept of probability more relatable and easier to grasp for readers.
Chapter 3:Descriptive and Inferential Statistics Chapter 3 builds on the concepts of probability, seamlessly connecting them to descriptive and inferential statistics. The author’s storytelling approach, such as the example involving a botanist, adds a practical and engaging dimension to statistics.
Chapter 4:Linear Algebra is a fundamental topic for data science, and this chapter covers it nicely. It starts with the basics of vectors and matrices, making it accessible to those new to the subject.
Chapter 5: The chapter on linear regression is well-structured and covers key aspects, including finding the best-fit line, correlation coefficients, and prediction intervals. Including stochastic gradient descent is a valuable addition, providing readers with a practical understanding of the topic.
Chapter 6: This chapter delves into logistic regression and classification, explaining concepts like R-squared, P-values, and confusion matrices. The discussion of ROC AUC and handling class imbalances is particularly useful.
Chapter 7: offers an overview of neural networks, discussing the forward and backward passes. While it provides a good foundation, it could benefit from more depth, especially considering the importance of neural networks in modern data science and machine learning.
Chapter 8: The final chapter offers valuable career guidance for data science enthusiasts. It provides insights and advice on navigating a career in this field, making it a helpful addition to the book.
Exercises and Examples One of the book’s strengths is its inclusion of exercises and example problems at the end of each chapter. These exercises challenge readers to apply what they’ve learned and reinforce their understanding of the concepts.
“Essential Math for Data Science” by Thomas Nield is a fantastic resource for individuals looking to strengthen their mathematical foundation in data science and machine learning. It is well-structured, and the author’s practical approach makes complex concepts more accessible. The book is an excellent supplementary resource, but some areas have room for additional depth. On a scale of 1 to 10, I rate it a solid 9.
As I delve deeper into the world of data science and machine learning, strengthening my mathematical foundation is just the beginning. “Essential Mathematics for Data Science” has provided me with a solid starting point. However, my learning journey continues, and I’m excited to explore these additional resources:
“Essential Math for AI: Next-Level Mathematics for Efficient and Successful AI Systems”
“Practical Linear Algebra for Data Science: From Core Concepts to Applications Using Python”
“Practical Statistics for Data Scientists: 50+ Essential Concepts Using R and Python”
Also, I value your insights, and if you have any recommendations or advice to share, please don’t hesitate to comment below. Your feedback is invaluable as I progress in my studies.
Apache Flink is a powerful data processing framework that handles batch and stream processing tasks in a single system. Flink provides a flexible and efficient architecture to process large-scale data in real time. In this article, we will discuss two important use cases for stream processing in Apache Flink: Stream as Append and Upsert in Dynamic Tables.
Stream as Append:
Stream as Append refers to continuously adding new data to an existing table. It is an everyday use case in real-time data processing where the new data must be combined with the current data to form a complete and up-to-date view. In Flink, this can be achieved using Dynamic Tables, which are a way to interact with stateful data streams and tables in Flink.
Suppose we have a sales data stream which a retail company is continuously generating. We want to store this data in a table and append the new data to the existing data.
Here is an example of how to achieve this in PyFlink:
from pyflink.table import StreamTableEnvironment, CsvTableSink, DataTypes from pyflink.table.descriptors import Schema, OldCsv, FileSystem
# create a StreamTableEnvironment st_env = StreamTableEnvironment.create()
# define the schema for the sales data stream sales_schema = Schema().field("item", DataTypes.STRING())\\ .field("price", DataTypes.DOUBLE())\\ .field("timestamp", DataTypes.TIMESTAMP())
# register the sales data stream as a table st_env.connect(FileSystem().path("/path/to/sales/data"))\\ .with_format(OldCsv().field_delimiter(",").field("item", DataTypes.STRING())\\ .field("price", DataTypes.DOUBLE())\\ .field("timestamp", DataTypes.TIMESTAMP()))\\ .with_schema(sales_schema)\\ .create_temporary_table("sales_table")
# define a table sink to store the sales data sales_sink = CsvTableSink(["/path/to/sales/table"], ",", 1, FileSystem.WriteMode.OVERWRITE)
# register the sales sink as a table st_env.register_table_sink("sales_table_sink", sales_sink)
# stream the sales data as-append into the sales sink st_env.from_path("sales_table").insert_into("sales_table_sink")
# execute the Flink job st_env.execute("stream-as-append-in-dynamic-table-example")
In this example, we first define the schema for the sales data stream using the Schema API. Then, we use the connect API to register the sales data stream as a table in the StreamTableEnvironment.
Next, the with_format API is used to specify the data format in the sales data stream, which is CSV in this example. Finally, the with_schema API is used to determine the schema of the data in the sales data stream.
Next, we define a table sink using the CsvTableSink API, and register it as a table in the StreamTableEnvironment using the register_table_sink API. Next, the insert_into API is used to stream the sales data as-append into the sales sink. Finally, we execute the Flink job using the implemented API.
Upsert refers to the process of updating an existing record or inserting a new record if it does not exist. It is an everyday use case in real-time data processing where the data might need to be updated with new information. In Flink, this can be achieved using Dynamic Tables, which provide a flexible way to interact with stateful data streams and tables in Flink.
Here is an example of how to implement upsert in dynamic tables using PyFlink:
from pyflink.datastreamimportStreamExecutionEnvironment, TimeCharacteristic from pyflink.tableimportStreamTableEnvironment, DataTypes from pyflink.table.descriptorsimportSchema, OldCsv, FileSystem
# create a StreamExecutionEnvironment and set the time characteristic to EventTime env = StreamExecutionEnvironment.get_execution_environment() env.set_stream_time_characteristic(TimeCharacteristic.EventTime)
# create a StreamTableEnvironment t_env = StreamTableEnvironment.create(env)
# register a dynamic table from the input stream with a unique key t_env.connect(FileSystem().path("/tmp/sales_data.csv")) \\ .with_format(OldCsv().field("transaction_id", DataTypes.BIGINT()) .field("product", DataTypes.STRING()) .field("amount", DataTypes.DOUBLE()) .field("timestamp", DataTypes.TIMESTAMP())) \\ .with_schema(Schema().field("transaction_id", DataTypes.BIGINT()) .field("product", DataTypes.STRING()) .field("amount", DataTypes.DOUBLE()) .field("timestamp", DataTypes.TIMESTAMP())) \\ .create_temporary_table("sales_table")
# specify the updates using a SQL query update_sql = "UPDATE sales_table SET amount = new_amount " \\ "FROM (SELECT transaction_id, SUM(amount) AS new_amount " \\ "FROM sales_table GROUP BY transaction_id)" t_env.sql_update(update_sql)
# start the data processing and sink the result to a CSV file t_env.execute("upsert_example")
In this example, we first create a StreamExecutionEnvironment and set the time characteristic to EventTime. Then, we create a StreamTableEnvironment and register a dynamic table from the input data stream using the connect method. Finally, the with_format method specifies the input data format, and the with_schema method defines the data schema.
Next, we specify the updates using a SQL query. In this case, we are updating the amount field of the sales_table by summing up the amounts for each transaction ID. Finally, the sql_update method is used to apply the updates to the dynamic table.
Finally, we start the data processing and sink the result to a CSV file using the execute method.
Stackademic
Thank you for reading until the end. Before you go:
Please consider clapping and following the writer! 👏