The token bucket algorithm is a technique for managing the frequency of system events. It keeps track of a bucket of tokens continuously added to at a set rate. These tokens can be viewed as units of capacity or permission that can be used to regulate the frequency at which events take place.
The token bucket algorithm limits the number of tokens that can be in the bucket at any given time, representing the maximum capacity or permission available to the system.
Tokens are added to the bucket at a fixed rate over time, starting with an empty bucket.
When an event occurs, it requests a token from the bucket.
If a token is available, it is removed from the bucket, allowing the event to occur.
If no tokens are available, the event is blocked or delayed until a token becomes available.
After each event, the algorithm checks whether the bucket has exceeded its capacity, and if so, additional tokens are discarded.
This ensures that the bucket is not too full and the system remains controlled.
Are you getting ready for a system design interview? It is critical to approach it with the proper mindset and preparation. System design deals with components at a higher level, so staying out of the trenches is vital. Instead, interviewers are looking for a high-level understanding of the system, the ability to identify key components and their interactions, and the ability to weigh trade-offs between various design options.
During the interview, pay attention to the trade-offs rather than the mechanics. You must make decisions about the system’s scalability, dependability, security, and cost-effectiveness. Understanding the trade-offs between these various aspects is critical to make informed decisions.
Here are a few examples to prove my point:
If you’re creating a social media platform, you must choose between scalability and cost-effectiveness. Should you, for example, use a scalable but expensive cloud platform or a less expensive but less scalable hosting service?
When creating an e-commerce website, you must make trade-offs between security and usability. Should you, for example, require customers to create an account with a complex password or let them checkout as a guest with a simpler password?
When designing a transportation management system, you must balance dependability and cost-effectiveness. Should you, for example, use real-time data to optimise routes and minimise delays, or should you rely on historical data to save money?
Are you getting ready for a system design interview? It is critical to approach it with the proper mindset and preparation. System design deals with components at a higher level, so staying out of the trenches is vital. Instead, interviewers are looking for a high-level understanding of the system, the ability to identify key components and their interactions, and the ability to weigh trade-offs between various design options.
During the interview, pay attention to the trade-offs rather than the mechanics. You must make decisions about the system’s scalability, dependability, security, and cost-effectiveness. Understanding the trade-offs between these various aspects is critical to make informed decisions.
Here are a few examples to prove my point:
If you’re creating a social media platform, you must choose between scalability and cost-effectiveness. Should you, for example, use a scalable but expensive cloud platform or a less expensive but less scalable hosting service?
When creating an e-commerce website, you must make trade-offs between security and usability. Should you, for example, require customers to create an account with a complex password or let them checkout as a guest with a simpler password?
When designing a transportation management system, you must balance dependability and cost-effectiveness. Should you, for example, use real-time data to optimise routes and minimise delays, or should you rely on historical data to save money?
Create Workflow: To read the above Kafka topic (RECON_KAFKA_TOPIC = “recon_details”) and after adding some changes write it back to Kafka (RECON_DONE_KAFKA_TOPIC = “recon_done”) for the analytics.
import json from kafka import KafkaConsumer from kafka import KafkaProducer
Apache Flink is a robust, open-source data processing framework that handles large-scale data streams and batch-processing tasks. One of the critical features of Flink is its architecture, which allows it to manage both batch and stream processing in a single system.
Consider a retail company that wishes to analyse sales data in real-time. They can use Flink’s stream processing capabilities to process sales data as it comes in and batch processing capabilities to analyse historical data.
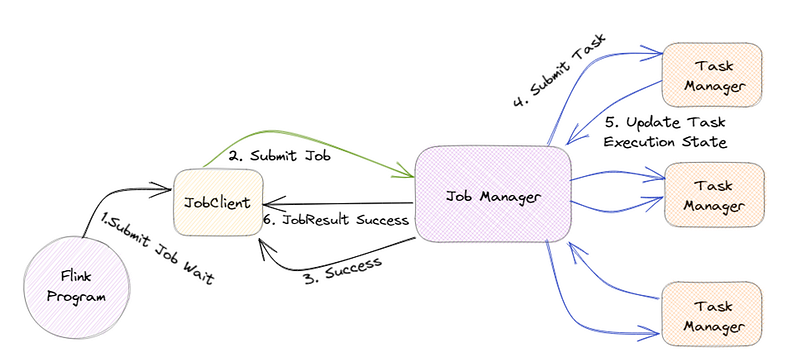
The JobManager is the central component of Flink’s architecture, and it is in charge of coordinating the execution of Flink jobs.
For example, if a large amount of data is submitted to Flink, the JobManager will divide it into smaller tasks and assign them to TaskManagers.
TaskManagers are responsible for executing the assigned tasks, and they can run on one or more nodes in a cluster. The TaskManagers are connected to the JobManager via a high-speed network, allowing them to exchange data and task information.
For example, when a TaskManager completes a task, it will send the results to the JobManager, who will then assign the next task.
Flink also has a distributed data storage system called the Distributed Data Management (DDM) system. It allows for storing and managing large data sets in a distributed manner across all the nodes in a cluster.
For example, imagine a company that wants to store and process petabytes of data, they can use Flink’s DDM system to store the data across multiple nodes, and process it in parallel.
Flink also has a built-in fault-tolerance mechanism, allowing it to recover automatically from failures. This is achieved by maintaining a consistent state across all the nodes in the cluster, which allows the system to recover from a failure by replaying the state from a consistent checkpoint.
For example, if a node goes down, Flink can automatically recover the data and continue processing without any interruption.
In addition, Flink also has a feature called “savepoints”, which allows users to take a snapshot of the state of a job at a particular point in time and later use this snapshot to restore the job to the same state.
For example, imagine a company is performing an update to their data processing pipeline and wants to test the new pipeline with the same data. They can use a savepoint to take a snapshot of the state of the job before making the update and then use that snapshot to restore the job to the same state for testing.
Flink also supports a wide range of data sources and sinks, including Kafka, Kinesis, and RabbitMQ, which allows it to integrate with other systems in a big data ecosystem easily.
For example, a company can use Flink to process streaming data from a Kafka topic and then sink the processed data into a data lake for further analysis.
The critical feature of Flink is that it handles batch and stream processing in a single system. To support this, Flink provides two main APIs: the Dataset API and the DataStream API.
The Dataset API is a high-level API for Flink that allows for batch processing of data. It uses a type-safe, object-oriented programming model and offers a variety of operations such as filtering, mapping, and reducing, as well as support for SQL-like queries. This API is handy for dealing with a large amount of data and is well suited for use cases such as analyzing historical sales data of a retail company.
On the other hand, the DataStream API is a low-level API for Flink that allows for real-time data stream processing. It uses a functional programming model and offers a variety of operations such as filtering, mapping, and reducing, as well as support for windowing and event time processing. This API is particularly useful for dealing with real-time data and is well-suited for use cases such as real-time monitoring and analysis of sensor data.
In conclusion, Apache Flink’s architecture is designed to handle large-scale data streams and batch-processing tasks in a single system. It provides a distributed data storage system, built-in fault tolerance and savepoints, and support for a wide range of data sources and sinks, making it an attractive choice for big data processing. With its powerful and flexible architecture, Flink can be used in various use cases, from real-time data processing to batch data processing, and can be easily integrated with other systems in a big data ecosystem.
Stackademic
Thank you for reading until the end. Before you go:
Please consider clapping and following the writer! 👏