An overview of the Lease-Based Coordination process: The Lease Coordinator manages the lease lifecycle, allowing one node to perform exclusive updates to the stock price data at a time.
The Lease-Based Coordination pattern offers an efficient mechanism to assign temporary control of a resource, such as stock price updates, to a single node. This approach prevents stale data and ensures that traders and algorithms always operate on consistent, real-time information.
The Problem: Ensuring Consistency and Freshness in Real-Time Trading
The diagram illustrates how uncoordinated updates across nodes lead to inconsistent stock prices ($100 at T1 and $95 at T2). The lack of synchronization results in conflicting values being served to the trader.
In a distributed stock trading environment, stock price data is replicated across multiple nodes to achieve high availability and low latency. However, this replication introduces challenges:
Stale Data Reads: Nodes might serve outdated price data to clients if updates are delayed or inconsistent across replicas.
Write Conflicts: Multiple nodes may attempt to update the same stock price simultaneously, leading to race conditions and inconsistent data.
High Availability Requirements: In trading systems, even a millisecond of downtime can lead to significant financial losses, making traditional locking mechanisms unsuitable due to latency overheads.
Example Problem Scenario: Consider a stock trading platform where Node A and Node B replicate stock price data for high availability. If Node A updates the price of a stock but Node B serves an outdated value to a trader, it may lead to incorrect trades and financial loss. Additionally, simultaneous updates from multiple nodes can create inconsistencies in the price history, causing a loss of trust in the system.
Lease-Based Coordination
The diagram illustrates the lease-based coordination mechanism, where the Lease Coordinator grants a lease to Node A for exclusive updates. Node A notifies Node B of its ownership, ensuring consistent data updates.
The Lease-Based Coordination pattern addresses these challenges by granting temporary ownership (a lease) to a single node, allowing it to perform updates and serve data exclusively for the lease duration. Here’s how it works:
Lease Assignment: A central coordinator assigns a lease to a node, granting it exclusive rights to update and serve a specific resource (e.g., stock prices) for a predefined time period.
Lease Expiry: The lease has a strict expiration time, ensuring that if the node fails or becomes unresponsive, other nodes can take over after the lease expires.
Renewal Mechanism: The node holding the lease must periodically renew it with the coordinator to maintain ownership. If it fails to renew, the lease is reassigned to another node.
This approach ensures that only the node with the active lease can update and serve data, maintaining consistency across the system.
Implementation: Lease-Based Coordination in Stock Trading
The diagram shows the lifecycle of a lease, starting with its assignment to Node A, renewal requests, and potential reassignment to Node B if Node A fails, ensuring consistent stock price updates.
Step 1: Centralized Lease Coordinator
A centralized service acts as the lease coordinator, managing the assignment and renewal of leases. For example, Node A requests a lease to update stock prices, and the coordinator grants it ownership for 5 seconds.
Step 2: Exclusive Updates
While the lease is active, Node A updates the stock price and serves consistent data to traders. Other nodes are restricted from making updates but can still read the data.
Step 3: Lease Renewal
Before the lease expires, Node A sends a renewal request to the coordinator. If Node A is healthy and responsive, the lease is extended. If not, the coordinator reassigns the lease to another node (e.g., Node B).
Step 4: Reassignment on Failure
If Node A fails or becomes unresponsive, the lease expires. The coordinator assigns a new lease to Node B, ensuring uninterrupted updates and data availability.
Practical Considerations and Trade-Offs
While Lease-Based Coordination provides significant benefits, there are trade-offs:
Clock Synchronization: Requires accurate clock synchronization between nodes to avoid premature or delayed lease expiry.
Latency Overhead: Frequent lease renewals can add slight latency to the system.
Single Point of Failure: A centralized lease coordinator introduces a potential bottleneck, though it can be mitigated with replication.
Stackademic 🎓
Thank you for reading until the end. Before you go:
Please consider clapping and following the writer! 👏
In distributed telecom systems, customer data is often stored across multiple nodes, with each node responsible for handling a subset, or shard, of the total data. When customer traffic spikes or new customers are added, certain nodes may become overloaded, leading to performance degradation. The Shard Rebalancing pattern addresses this challenge by dynamically redistributing data across nodes, ensuring balanced load and optimal access speeds.
The Problem: Uneven Load Distribution in Telecom Data Systems
Illustration of uneven shard distribution across nodes in a telecom system. Node 1 is overloaded with high-traffic shards, while Node 2 remains underutilized. Redistribution of shards can help balance the load.
Telecom providers handle vast amounts of customer data, including call records, billing information, and service plans. This data is typically partitioned across multiple nodes to support scalability and high availability. However, several challenges can arise:
Skewed Data Distribution: Certain shards may contain data for high-traffic regions or customers, causing uneven load distribution across nodes.
Dynamic Traffic Patterns: Events such as promotional campaigns or network outages can lead to sudden traffic spikes in specific shards, overwhelming the nodes handling them.
Scalability Challenges: As the number of customers grows, adding new nodes or redistributing shards becomes necessary to prevent performance bottlenecks.
Example Problem Scenario: A telecom provider stores customer data by region, with each shard representing a geographical area. During a popular live-streaming event, customers in one region (e.g., a metropolitan city) generate significantly higher traffic, overwhelming the node responsible for that shard. Customers experience delayed responses for call setup, billing inquiries, and plan updates, degrading the overall user experience.
Shard Rebalancing: Dynamically Redistributing Data
Shard Rebalancing process during load redistribution in a telecom system. Node 1 redistributes Shards 1 and 2 to balance load across Node 2 and a newly joined node, Host 3. This ensures consistent performance across the system.
The Shard Rebalancing pattern solves this problem by dynamically redistributing data across nodes to balance load and ensure consistent performance. Here’s how it works:
Monitoring Load: The system continuously monitors load on each node, identifying hotspots where specific shards are under heavy traffic or processing.
Redistribution Logic: When a node exceeds its load threshold, the system redistributes part of its data to less-utilized nodes. This may involve splitting a shard into smaller pieces or migrating entire shards.
Minimal Downtime: Shard rebalancing is performed with minimal disruption to ensure ongoing data access for customers.
Telecom Customer Data During Peak Events
Problem Context:
A large telecom provider offers video-on-demand services alongside traditional voice and data plans. During peak events, such as the live-streaming of a global sports final, traffic spikes in urban regions with dense populations. The node handling the shard for that region becomes overloaded, causing delays in streaming access and service requests.
Shard Rebalancing in Action:
Load Monitoring: The system detects that the shard representing the urban region has reached 90% of its resource capacity.
2. Dynamic Redistribution:
The system splits the shard into smaller sub-shards (e.g., splitting based on city districts or user groups).
One sub-shard remains on the original node, while the others are migrated to underutilized nodes in the cluster.
3. Seamless Transition: DNS routing updates ensure customer requests are directed to the new nodes without downtime or manual intervention.
4. Balanced Load: The system achieves an even distribution of traffic, reducing response times for all users.
Shard rebalancing in action during a peak traffic event in an urban region. The Load Monitor detects high utilization of Shard 1 at Node 1, prompting shard splitting and migration to Node 2 and a newly added Node 3, ensuring balanced system performance.
Results:
Reduced latency for live-streaming customers in the overloaded region.
Improved system resilience during future traffic spikes.
Efficient utilization of resources across the entire cluster.
Practical Considerations and Trade-Offs
While Shard Rebalancing provides significant benefits, there are challenges to consider:
Data Migration Overheads: Redistributing shards involves data movement, which can temporarily increase network usage.
Latency During Rebalancing: Although designed for minimal disruption, some delay may occur during shard redistribution.
The Shard Rebalancing pattern is crucial for maintaining balanced loads and high performance in distributed telecom systems. By dynamically redistributing data across nodes, it ensures efficient resource utilization and provides optimal user experiences, even during unexpected traffic surges.
Stackademic 🎓
Thank you for reading until the end. Before you go:
Please consider clapping and following the writer! 👏
In distributed supply chain systems, maintaining accurate inventory data across multiple locations is crucial. When inventory records are updated independently in different warehouses, data conflicts can arise due to network partitions or concurrent updates. The Version Vector pattern addresses these challenges by tracking updates across nodes and reconciling conflicting changes.
The Problem: Concurrent Updates and Data Conflicts in Distributed Inventory Systems
This diagram shows how Node A and Node B independently update the same inventory record, leading to potential conflicts.
In a supply chain environment, inventory records are updated across multiple warehouses, each maintaining a local version of the data. Ensuring that inventory information remains consistent across locations is challenging due to several key issues:
Concurrent Updates: Different warehouses may update inventory levels at the same time. For instance, one location might log an inbound shipment, while another logs an outbound transaction. Without a mechanism to handle these concurrent updates, the system may show conflicting inventory levels.
Network Partitions: Network issues can cause temporary disconnections between nodes, allowing updates to happen independently in different locations. When the network connection is restored, each node may have different versions of the same inventory record, leading to discrepancies.
Data Consistency Requirements: Accurate inventory data is critical to avoid overstocking, stockouts, and operational delays. If inventory levels are inconsistent across nodes, the supply chain can be disrupted, causing missed orders and inaccurate stock predictions.
Imagine a scenario where a supply chain system manages inventory levels for multiple warehouses. Warehouse A logs a received shipment, increasing stock levels, while Warehouse B simultaneously logs a shipment leaving, reducing stock. Without a way to reconcile these changes, the system could show incorrect inventory counts, impacting operations and customer satisfaction.
Version Vector: Tracking Updates for Conflict Resolution
This diagram illustrates a version vector for three nodes, showing how Node A updates the inventory and increments its counter in the version vector.
The Version Vector pattern addresses these issues by assigning a unique version vector to each inventory record, which tracks updates from each node. This version vector allows the system to detect conflicts and reconcile them effectively. Here’s how it works:
Version Vector: Each inventory record is assigned a version vector, an array of counters where each counter represents the number of updates from a specific node. For example, in a system with three nodes, a version vector [2, 1, 0] indicates that Node A has made two updates, Node B has made one update, and Node C has made none.
Conflict Detection: When nodes synchronize, they exchange version vectors. If a node detects that another node has updates it hasn’t seen, it identifies a potential conflict and triggers conflict resolution.
Conflict Resolution: When conflicts are detected, the system applies pre-defined conflict resolution rules to determine the final inventory level. Common strategies include merging updates or prioritizing certain nodes to ensure data consistency.
The Version Vector pattern ensures that each node has an accurate view of inventory data, even when concurrent updates or network partitions occur.
Implementation: Resolving Conflicts with Version Vectors in Inventory Management
In a distributed supply chain with multiple warehouses (e.g., three nodes), here’s how version vectors track and resolve conflicts:
Step 1: Initializing Version Vectors
Each inventory record starts with a version vector initialized to [0, 0, 0] for three nodes (Node A, Node B, and Node C). This vector keeps track of the number of updates each node has applied to the inventory record.
Step 2: Incrementing Version Vectors on Update
When a warehouse updates the inventory, it increments its respective counter in the version vector. For example, if Node A processes an incoming shipment, it updates the version vector to [1, 0, 0], indicating that it has made one update.
Step 3: Conflict Detection and Resolution
This sequence diagram shows the conflict detection process. Node A and Node B exchange version vectors, detect a conflict, and resolve it using predefined rules.
As nodes synchronize periodically, they exchange version vectors. If Node A has a version vector [2, 0, 0] and Node B has [0, 1, 0], both nodes recognize that they have unseen updates from each other, signaling a conflict. The system then applies conflict resolution rules to reconcile these changes and determine the final inventory count.
The diagram below illustrates how version vectors track updates across nodes and detect conflicts in a distributed supply chain. Each node’s version vector reflects its update history, enabling the system to accurately identify and manage conflicting changes.
Consistent Inventory Data Across Warehouses: Advantages of Version Vectors
Accurate Conflict Detection: Version vectors allow the system to detect concurrent updates, minimizing the risk of unnoticed conflicts and data discrepancies.
Effective Conflict Resolution: By tracking updates from each node, the system can apply targeted conflict resolution strategies to ensure inventory data remains accurate.
Fault Tolerance: In case of network partitions, nodes can operate independently. When connectivity is restored, nodes can reconcile updates, maintaining consistency across the entire network.
Practical Considerations and Trade-Offs
While version vectors offer substantial benefits, there are some trade-offs to consider in their implementation:
Vector Size: The version vector’s size grows with the number of nodes, which can increase storage requirements in larger systems.
Complexity of Conflict Resolution: Defining rules for conflict resolution can be complex, especially if nodes make contradictory updates.
Operational Overhead: Synchronizing version vectors across nodes requires extra network communication, which may affect performance in large-scale systems.
Eventual Consistency in Supply Chain Inventory Management
This diagram illustrates how nodes in a distributed supply chain eventually synchronize their inventory records after resolving conflicts, achieving consistency across all warehouses.
The Version Vector pattern supports eventual consistency by allowing each node to update inventory independently. Over time, as nodes exchange version vectors and resolve conflicts, the system converges to a consistent state, ensuring that inventory data across warehouses remains accurate and up-to-date.
The Version Vector for Conflict Resolution pattern effectively manages data consistency in distributed supply chain systems. By using version vectors to track updates, organizations can prevent conflicts and maintain data integrity, ensuring accurate inventory management and synchronization across all locations.
Stackademic 🎓
Thank you for reading until the end. Before you go:
Please consider clapping and following the writer! 👏
The Saga pattern is an architectural pattern utilized for managing distributed transactions in microservices architectures. It ensures data consistency across multiple services without relying on distributed transactions, which can be complex and inefficient in a microservices environment.
Key Concepts of the Saga Pattern
In the Saga pattern, a business process is broken down into a series of local transactions. Each local transaction updates the database and publishes an event or message to trigger the next transaction in the sequence. This approach helps maintain data consistency across services by ensuring that each step is completed before moving to the next one.
Types of Saga Patterns
There are several variations of the Saga pattern, each suited to different scenarios:
Choreography-based Saga: Each service listens for events and decides whether to proceed with the next step based on the events it receives. This decentralized approach is useful for loosely coupled services.
Orchestration-based Saga: A central coordinator, known as the orchestrator, manages the sequence of actions. This approach provides a higher level of control and is beneficial when precise coordination is required.
State-based Saga: Uses a shared state or state machine to track the progress of a transaction. Microservices update this state as they execute their actions, guiding subsequent steps.
Reverse Choreography Saga: An extension of the Choreography-based Saga where services explicitly communicate about how to compensate for failed actions.
Event-based Saga: Microservices react to events generated by changes in the system, performing necessary actions or compensations asynchronously.
Challenges Addressed by the Saga Pattern
The Saga pattern solves the problem of maintaining data consistency across multiple microservices in distributed transactions. It addresses several key challenges that arise in microservices architectures:
Distributed Transactions: In a microservices environment, a single business transaction often spans multiple services, each with its own database. Traditional ACID transactions don’t work well in this distributed context.
Data Consistency: Ensuring data consistency across different services and their databases is challenging when you can’t use a single, atomic transaction.
Scalability and Performance: Two-phase commit (2PC) protocols, which are often used for distributed transactions, can lead to performance issues and reduced scalability in microservices architectures.
Solutions Provided by the Saga Pattern
The Saga pattern solves these problems by:
Breaking down distributed transactions into a sequence of local transactions, each handled by a single service.
Using compensating transactions to undo changes if a step in the sequence fails, ensuring eventual consistency.
Flexibility in transaction management, allowing services to be added, modified, or removed without significantly impacting the overall transactional flow.
Better scalability by allowing each service to manage its own local transaction independently.
Improving fault tolerance by providing mechanisms to handle and recover from failures in the transaction sequence.
Visibility into the transaction process, which aids in debugging, auditing, and compliance.
Implementation Approaches
Choreography-Based Sagas
Decentralized Control: Each service involved in the saga listens for events and reacts to them independently, without a central controller.
Event-Driven Communication: Services communicate by publishing and subscribing to events.
Autonomy and Flexibility: Services can be added, removed, or modified without significantly impacting the overall system.
Scalability: Choreography can handle complex and frequent interactions more flexibly, making it suitable for highly scalable systems.
Orchestration-Based Sagas
Centralized Control: A central orchestrator manages the sequence of transactions, directing each service on what to do and when.
Command-Driven Communication: The orchestrator sends commands to services to perform specific actions.
Visibility and Control: The orchestrator has a global view of the saga, making it easier to manage and troubleshoot.
Choosing Between Choreography and Orchestration
When to Use Choreography
When you want to avoid creating a single point of failure.
When services need to be highly autonomous and independent.
When adding or removing services without disrupting the overall flow is a priority.
When to Use Orchestration
When you need to guarantee a specific order of execution.
When centralized control and visibility are crucial for managing complex workflows.
When you need to manage the lifecycle of microservices execution centrally.
Hybrid Approach
In some cases, a combination of both approaches can be beneficial. Choreography can be used for parts of the saga that require high flexibility and autonomy, while orchestration can manage parts that need strict control and coordination.
Challenges and Considerations
Complexity: Implementing SAGA can be more complex than traditional transactions.
Lack of Isolation: Intermediate states are visible, which can lead to consistency issues.
Error Handling: Designing and implementing compensating transactions can be tricky.
Testing: Thorough testing of all possible scenarios is crucial but can be challenging.
The Saga pattern is powerful for managing distributed transactions in microservices architectures, offering a balance between consistency, scalability, and resilience. By carefully selecting the appropriate implementation approach, organizations can effectively address the challenges of distributed transactions and maintain data consistency across their services.
Stackademic 🎓
Thank you for reading until the end. Before you go:
Please consider clapping and following the writer! 👏
Today during an Azure learning session focused on data security and governance, our instructor had to leave unexpectedly due to a personal emergency. Reflecting on the discussion and drawing from my background in fintech and solution architecture, I believe it would be beneficial to explore an architecture pattern relevant to our conversation: the Bulkhead Architecture Pattern.
Inspired by ship design, the Bulkhead architecture pattern divides the base of a ship into partitions called bulkheads. This ensures that if there’s a leak in one section, it doesn’t sink the entire ship; only the affected partition fills with water. Translating this principle to software architecture, the pattern focuses on fault isolation by decomposing a monolithic architecture into a microservices architecture.
Use Case: Bank Reconciliation Reporting
Consider a scenario involving trade data across various regions such as APAC, EMEA, LATAM, and NAM. Given the regulatory challenges related to cross-country data movement, ensuring proper data governance when consolidating data in a data warehouse environment becomes crucial. Specifically, it is essential to manage the challenge of ensuring that data from India cannot be accessed from the NAM region and vice versa. Additionally, restricting data movement at the data centre level is critical.
Microservices Isolation
Microservices A, B, C: Each microservice is deployed in its own Azure Kubernetes Service (AKS) cluster or Azure App Service.
Independent Databases: Each microservice uses a separate database instance, such as Azure SQL Database or Cosmos DB, to avoid single points of failure.
Network Isolation
Virtual Networks (VNets): Each microservice is deployed in its own VNet. Use Network Security Groups (NSGs) to control inbound and outbound traffic.
Private Endpoints: Secure access to Azure services (e.g., storage accounts, databases) using private endpoints.
Load Balancing and Traffic Management
Azure Front Door: Provides global load balancing and application acceleration for microservices.
Application Gateway: Offers application-level routing and web application firewall (WAF) capabilities.
Traffic Manager: A DNS-based traffic load balancer for distributing traffic across multiple regions.
Service Communication
Service Bus: Use Azure Service Bus for decoupled communication between microservices.
Event Grid: Event-driven architecture for handling events across microservices.
Fault Isolation and Circuit Breakers
Polly: Implement circuit breakers and retries within microservices to handle transient faults.
Azure Functions: Use serverless functions for non-critical, independently scalable tasks.
Data Partitioning and Isolation
Sharding: Partition data across multiple databases to improve performance and fault tolerance.
Data Sync: Use Azure Data Sync to replicate data across regions for redundancy.
Monitoring and Logging
Azure Monitor: Centralized monitoring for performance and availability metrics.
Application Insights: Deep application performance monitoring and diagnostics.
Log Analytics: Aggregated logging and querying for troubleshooting and analysis.
Advanced Threat Protection
Azure Defender for Storage: Enable Azure Defender for Storage to detect unusual and potentially harmful attempts to access or exploit storage accounts.
Key Points
Isolation: Each microservice and its database are isolated in separate clusters and databases.
Network Security: VNets and private endpoints ensure secure communication.
Resilience: Circuit breakers and retries handle transient faults.
Monitoring: Centralized monitoring and logging for visibility and diagnostics.
Scalability: Each component can be independently scaled based on load.
Bulkhead Pattern Concepts
Isolation
The primary goal of the Bulkhead pattern is to isolate different parts of a system to contain failures within a specific component, preventing them from cascading and affecting the entire system. This isolation can be achieved through various means such as separate thread pools, processes, or containers.
Fault Tolerance
By containing faults within isolated compartments, the Bulkhead pattern enhances the system’s ability to tolerate failures. If one component fails, the rest of the system can continue to operate normally, thereby improving overall reliability and stability.
Resource Management
The pattern helps in managing resources efficiently by allocating specific resources (like CPU, memory, and network bandwidth) to different components. This prevents resource contention and ensures that a failure in one component does not exhaust resources needed by other components.
Implementation Examples in K8s
Kubernetes
An example of implementing the Bulkhead pattern in Kubernetes involves creating isolated containers for different services, each with its own CPU and memory resources and limits. This configuration is for a service called payment-processing.
The payment-processing service is allocated 128Mi of memory and 500m of CPU as a request, with limits set to 256Mi of memory and 2 CPUs.
The order-management service has its own isolated resources, with 64Mi of memory and 250m of CPU as a request, and limits set to 128Mi of memory and 1 CPU.
The inventory-control service is given 96Mi of memory and 300m of CPU as a request, with limits set to 192Mi of memory and 1.5 CPUs.
This setup ensures that each service operates within its own resource limits, preventing any single service from exhausting resources and affecting the others.
Hystrix
Hystrix, a Netflix API for latency and fault tolerance, uses the Bulkhead pattern to limit the number of concurrent calls to a component. This is achieved through thread isolation, where each component is assigned a separate thread pool, and semaphore isolation, where callers must acquire a permit before making a request. This prevents the entire system from becoming unresponsive if one component fails.
In AWS App Mesh, the Bulkhead pattern can be implemented at the service-mesh level. For example, in an e-commerce application with different API endpoints for reading and writing prices, resource-intensive write operations can be isolated from read operations by using separate resource pools. This prevents resource contention and ensures that read operations remain unaffected even if write operations experience a high load.
Benefits
Fault Containment: Isolates faults within specific components, preventing them from spreading and causing systemic failures.
Improved Resilience: Enhances the system’s ability to withstand unexpected failures and maintain stability.
Performance Optimization: Allocates resources more efficiently, avoiding bottlenecks and ensuring consistent performance.
Scalability: Allows independent scaling of different components based on workload demands.
Security Enhancement: Reduces the attack surface by isolating sensitive components, limiting the impact of security breaches.
The Bulkhead pattern is a critical design principle for constructing resilient, fault-tolerant, and efficient systems by isolating components and managing resources effectively.
Stackademic 🎓
Thank you for reading until the end. Before you go:
Please consider clapping and following the writer! 👏
Scaling an application is a challenging task. To scale effectively, you often need to increase the number of web servers, application servers, and database servers. However, this can make your architecture complex due to the need for high performance and scalability to serve thousands of concurrent users.
Horizontal scaling of the database layer typically involves sharding, which adds further complexity and makes it difficult to manage.
In general, Space-Based Architecture (SBA) addresses the challenge of creating highly scalable and elastic systems capable of handling a vast number of concurrent users and operations. Traditional architectures often struggle with performance bottlenecks due to direct interactions with the database for transactional data, leading to limitations in scalability and elasticity.
What is Space-Based Architecture (SBA)?
In Space-Based Architecture (SBA), you scale your application by removing the database and instead using memory grids to manage the data. Instead of scaling a particular tier in your application, you scale the entire architecture together as a unified process. SBA is widely used in distributed computing to increase the scalability and performance of a solution. This architecture is based on the concept of a tuple space.
Note: A tuple space is a shared memory object that provides operations to store and retrieve ordered sets of data, called tuples. It is an implementation of the associative memory paradigm for parallel/distributed computing, allowing multiple processes to access and manipulate tuples concurrently.
Goals of SBA
High Scalability and Elasticity:
· Efficiently managing and processing millions of concurrent users and transactions without direct database interactions.
· Enabling rapid scaling from a small number of users to hundreds of thousands or more within milliseconds.
Performance Optimization:
· Reducing latency by utilizing in-memory data grids and caching mechanisms instead of direct database reads and writes.
· Ensuring quick data access times measured in nanoseconds for a seamless user experience.
Eventual Consistency:
· Maintaining eventual consistency across distributed processing units through replicated caching and asynchronous data writes to the database.
Decoupling Database Dependency:
· Minimizing the dependency on the database for real-time transaction processing to prevent database bottlenecks and improve system responsiveness.
Handling High Throughput:
Managing high throughput demands without overwhelming the database by leveraging in-memory data replication and distributed processing units.
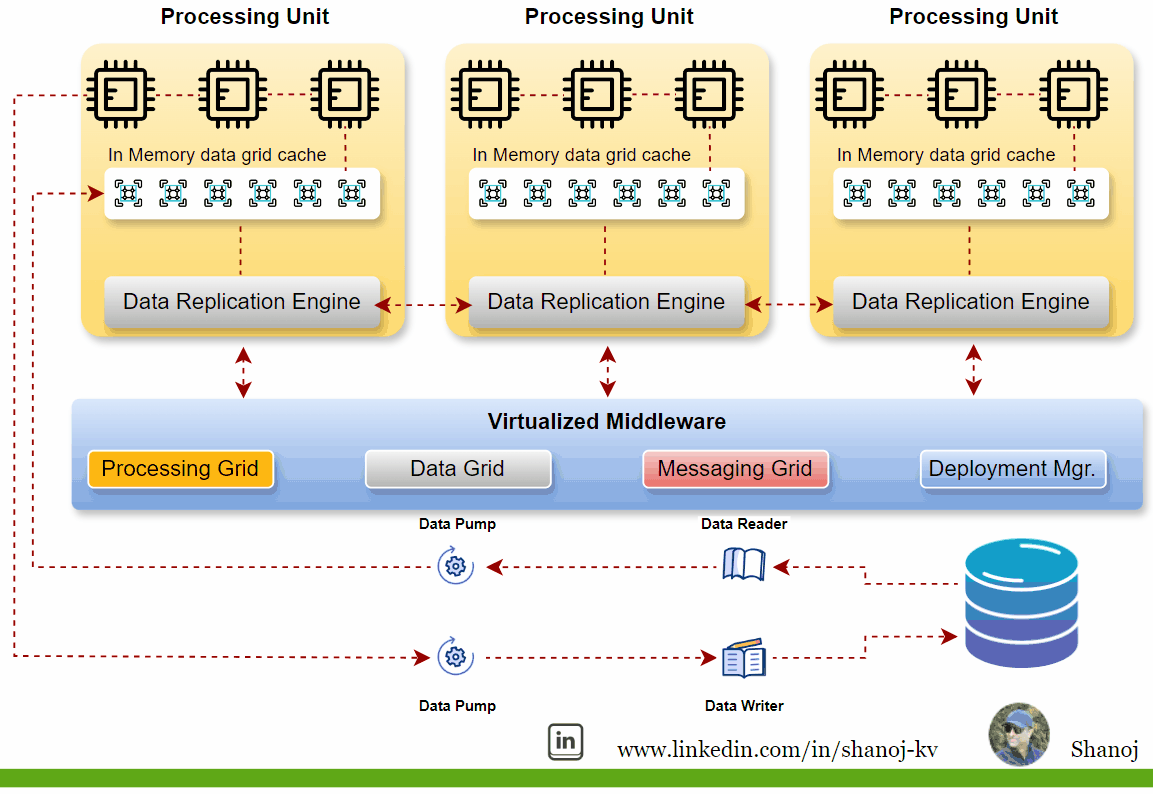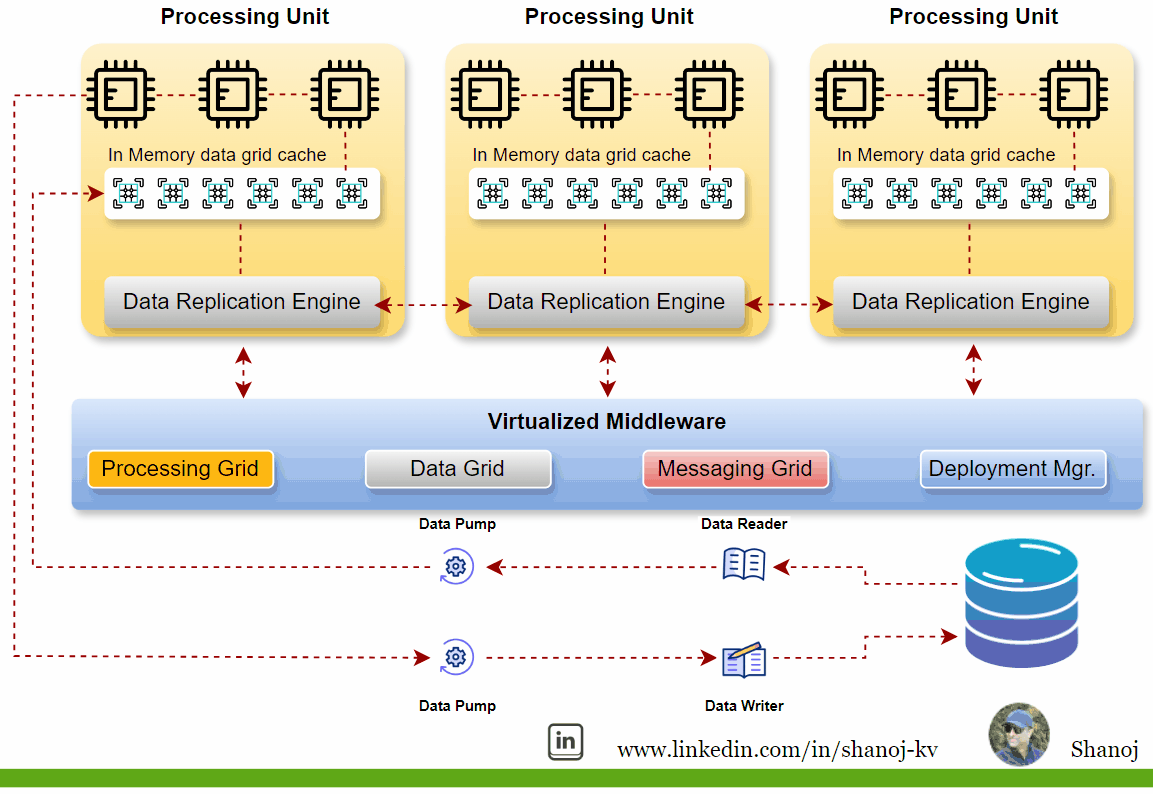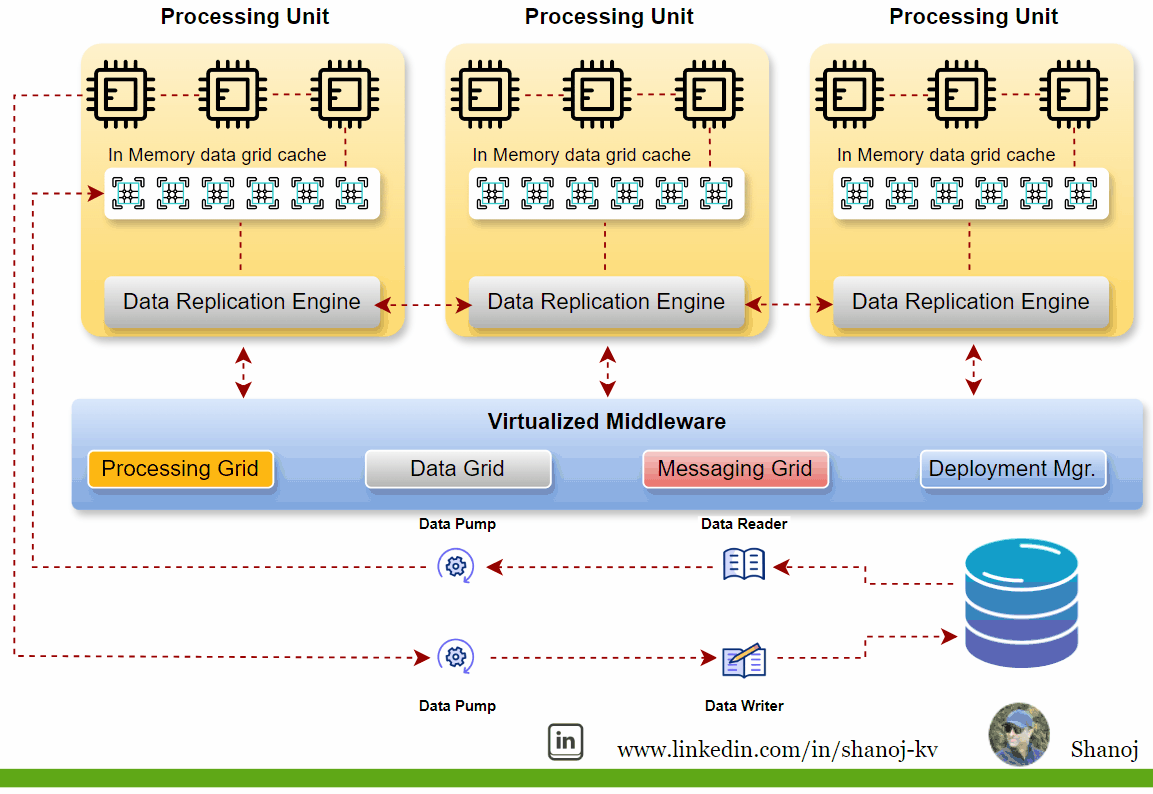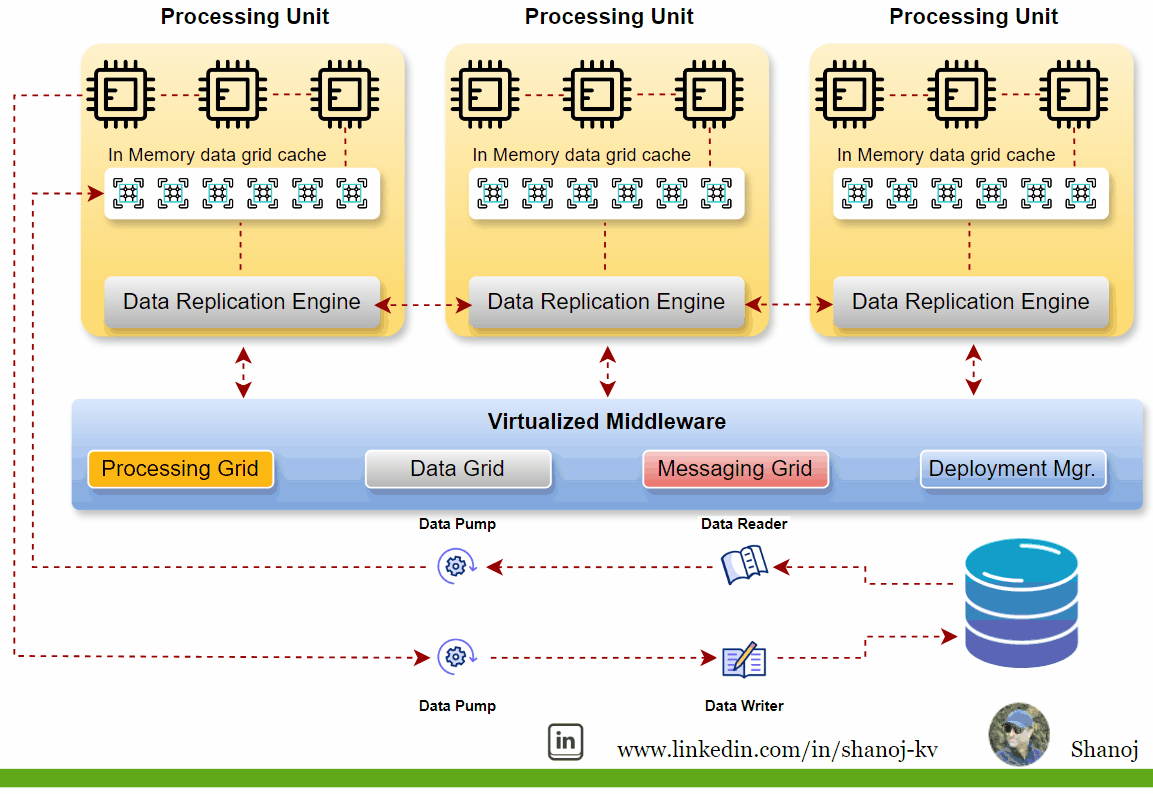
Key Components of SBA
Processing Units (PU):
These are individual nodes or containers that encapsulate the processing logic and the data they operate on. Each PU is responsible for executing business logic and can be replicated or partitioned for scalability and fault tolerance. They typically include web-based components, backend business logic, an in-memory data grid, and a replication engine.
Virtualized Middleware:
This layer handles shared infrastructure concerns and includes:
· Data Grid: A crucial component that allows requests to be assigned to any available processing unit, ensuring high performance and reliability. The data grid is responsible for synchronizing data between the processing units by building the tuple space.
· Messaging Grid: Manages the flow of incoming transactions and communication between services.
· Processing Grid: Enables parallel processing of events among different services based on the master/worker pattern.
· Deployment Manager: Manages the startup and shutdown of PUs, starts new PUs to handle additional load, and shuts down PUs when no longer needed.
· Data Pumps and Data Readers/Writers: Data pumps marshal data between the database and the processing units, ensuring consistent data updates across nodes.
Now you might be naturally thinking, what makes SBA different from a traditional memory cache database?
Differences Between SBA and Memory Cache Databases
Data Consistency:
· SBA: Uses an eventual consistency model, where updates are asynchronously propagated across nodes, ensuring eventual convergence without the need for immediate consistency, which can introduce significant performance overhead.
· Memory Cache Database: Typically uses strong consistency models, ensuring immediate consistency across all nodes, which can impact performance.
Scalability:
· SBA: Achieves linear scalability by adding more processing units (PUs) as needed, ensuring the system can handle increasing workloads without performance degradation.
· Memory Cache Database: Scalability is often limited by the underlying database architecture and can be more complex to scale horizontally.
Data Replication:
· SBA: Replicates data across multiple nodes to ensure fault tolerance and high availability. In the event of a node failure, the system can seamlessly recover by accessing replicated data from other nodes.
· Memory Cache Database: Data replication is used for performance and availability but can be more complex to manage and maintain consistency.
Data Grid:
· SBA: Utilizes a distributed data grid that allows requests to be assigned to any available processing unit, ensuring high performance and reliability.
· Memory Cache Database: Typically uses a centralized cache that can become a bottleneck as the system scales.
Processing:
· SBA: Enables parallel processing across multiple nodes, leading to improved throughput and response times.
· Memory Cache Database: Processing is typically done within the database or cache layer, which can be less scalable and efficient.
Deployment:
· SBA: Supports elastic scalability by adding or removing nodes as needed, ensuring the system can handle increased workloads without compromising performance or data consistency.
· Memory Cache Database: Deployment and scaling can be more complex and often require significant infrastructure changes.
Cost:
· SBA: Can be more cost-effective by leveraging distributed computing and in-memory processing, reducing the need for expensive hardware and infrastructure upgrades.
· Memory Cache Database: Can be more expensive due to the need for high-performance hardware and infrastructure to support the cache layer.
Now you might be wondering, is SBA suitable for every scenario?
Limitations of SBA
High Data Synchronization and Consistency Requirements:
Systems that require immediate data consistency and high synchronization across all components will not benefit from SBA due to its eventual consistency model.
The delay in synchronizing data with the database may not meet the needs of applications requiring real-time consistency.
Large Volumes of Transactional Data:
Applications needing to store and manage massive amounts of transactional data (e.g., terabytes) are not suitable for SBA.
Keeping such large volumes of data in memory is impractical and may exceed the memory capacity of available hardware.
Budget and Time Constraints:
Projects with strict budget and time constraints are likely to overrun their resources due to the technical complexity of implementing SBA.
The initial setup and implementation are resource-intensive, requiring significant investment in both time and money.
Technical Complexity:
The high technical complexity of SBA makes it challenging to implement, maintain, and troubleshoot.
Organizations lacking the necessary expertise and experience may find it difficult to manage the intricacies of SBA.
Cost Considerations:
The cost of maintaining in-memory data grids and replicated caching can be prohibitive, especially for smaller organizations or projects with limited budgets.
The infrastructure required to support SBA’s scalability and performance may be expensive to acquire and maintain.
Limited Agility:
SBA offers limited agility compared to other architectural styles due to its complex setup and eventual consistency model.
Changes and updates to the system may require significant effort and coordination across distributed processing units.
Now, let’s dive into some use cases and solutions that demonstrate the power of SBA.
Use Cases and Solutions
Space-Based Architecture (SBA) addresses several critical challenges that traditional architectures face, particularly in high-transaction, high-availability, and variable load environments.
Scalability Bottlenecks:
· Problem: Traditional architectures often struggle to scale horizontally due to limitations in centralized data storage and processing.
· Solution: SBA enables horizontal scalability by distributing processing units (PUs) across multiple nodes. Each PU can handle a portion of the workload independently, allowing the system to scale out by simply adding more PUs.
High Availability and Fault Tolerance:
· Problem: Ensuring high availability and fault tolerance is challenging in monolithic or tightly coupled systems.
· Solution: SBA enhances fault tolerance through redundancy and data replication. Each PU operates independently, and data is replicated across multiple PUs. If one PU fails, others can take over, ensuring continuous availability and minimal downtime.
Performance Issues:
· Problem: Traditional systems often rely heavily on relational databases, leading to performance bottlenecks due to slow disk I/O and limited scalability of single-node databases.
· Solution: SBA leverages in-memory data grids, which provide faster data access and reduce the dependency on disk-based storage, significantly improving response times and overall system performance.
Handling Variable and Unpredictable Loads:
· Problem: Many applications experience variable and unpredictable workloads, such as seasonal spikes in e-commerce or fluctuating traffic in social media platforms.
· Solution: SBA’s elastic nature allows it to automatically adjust to varying loads by adding or removing PUs as needed, ensuring the system can handle peak loads without performance degradation.
Reducing Single Points of Failure:
· Problem: Centralized components, such as single database servers or monolithic application servers, can become single points of failure.
· Solution: SBA decentralizes processing and storage, eliminating single points of failure. Each PU can function independently, and the system can continue to operate even if some PUs fail.
Complex Data Management:
· Problem: Managing large volumes of data and ensuring its consistency, availability, and partitioning across a distributed system can be complex.
· Solution: SBA uses distributed data stores and in-memory data grids to manage data efficiently, ensuring data consistency and availability through replication and partitioning strategies.
Simplifying Deployment and Maintenance:
· Problem: Deploying and maintaining traditional monolithic applications can be cumbersome.
· Solution: SBA’s modular nature simplifies deployment and maintenance. Each PU can be developed, tested, and deployed independently, reducing the risk of system-wide issues during updates or maintenance.
Latency and Real-Time Processing:
· Problem: Real-time processing and low-latency requirements are difficult to achieve with traditional architectures.
· Solution: SBA’s use of in-memory data grids and asynchronous messaging grids ensures low latency and real-time processing capabilities, crucial for applications requiring immediate data processing and response.
Space-Based Architecture addresses several significant challenges faced by traditional architectures, making it an ideal choice for applications requiring high scalability, performance, availability, and resilience. By distributing processing and data management across independent units, SBA ensures that systems can handle modern demands efficiently and effectively.
Stackademic 🎓
Thank you for reading until the end. Before you go:
Please consider clapping and following the writer! 👏
Event-Driven Architecture (EDA) is a software design paradigm that emphasizes producing, detecting, and reacting to events. Two important architectural concepts within EDA are:
Asynchrony
Asynchrony in EDA refers to the ability of services to communicate without waiting for immediate responses. This is crucial for building scalable and resilient systems. Here are key points about asynchrony:
Decoupled Communication: Services can send messages or events without needing to wait for a response, allowing them to continue processing other tasks. This decoupling enhances system performance and scalability.
Example: Service A invokes Service B with a request and receives a response asynchronously. Similarly, Service C submits a batch job to Service D and receives an acknowledgement, then polls for the job status and gets updates later
Event-Driven Communication
Event-driven communication is the core of EDA, where events trigger actions across different services. This approach ensures that systems can react to changes in real-time and remain loosely coupled. Key aspects include:
Event Producers and Consumers: Events are generated by producers and consumed by interested services. This model supports real-time processing and decoupling of services.
Example: Service C submits a batch job to Service D and receives an acknowledgement. Upon completion, Service D sends a notification to Service C, allowing it to react to the event without polling
Key Definitions
Event-driven architecture (EDA): Uses events to communicate between decoupled applications asynchronously.
Event Producer or Publisher: Generates events, such as account creation or deletion.
Event Broker: Receives events from producers and routes them to appropriate consumers.
Event Consumer or Subscriber: Receives and processes events from the broker.
Characteristics of Event Components
Event Producer:
Agnostic of consumers
Adds producer’s identity
Conforms to a schema
Unique event identifier
Adds just the required data
Event Consumer:
Idempotent (can handle duplicate events without adverse effects)
Ordering not guaranteed
Ensures event authenticity
Stores events and processes them
Event Broker:
Handles multiple publishers and subscribers
Routes events to multiple targets
Supports event transformation
Maintains a schema repository
Important Concepts
Event: Something that has already happened in the system.
Service Choreography: A coordinated sequence of actions across multiple microservices to accomplish a business process. It promotes service decoupling and asynchrony, enabling extensibility.
Common Mistakes
Overly complex event-driven designs can lead to tangled architectures.
Overly complex event-driven designs can lead to tangled architectures, which are difficult to manage and maintain. Here are some real-world examples and scenarios illustrating this issue:
Example 1: Microservices Overload
In a large-scale microservices architecture, each service may generate and process numerous events. For example, an e-commerce platform might include services for inventory, orders, payments, shipping, and notifications. If each of these services creates events for every change in state and processes events from various other services, the number of event interactions can grow significantly. This can result in a scenario where:
Event Storming: Too many events are being produced and consumed, making it hard to track which service is responsible for what.
Service Coupling: Services become tightly coupled through their event dependencies, making it difficult to change one service without impacting others.
Debugging Challenges: Tracing the flow of events to diagnose issues becomes complex, as events might trigger multiple services in unpredictable ways.
Example 2: Financial Transactions
In a financial system, different services might handle account management, transaction processing, fraud detection, and customer notifications. If these services are designed to emit and listen to numerous events, the architecture can become tangled:
Complex Event Chains: A single transaction might trigger a cascade of events across multiple services, making it hard to ensure data consistency and integrity.
Latency Issues: The time taken for events to propagate through the system can introduce latency, affecting the overall performance.
Security Concerns: With multiple services accessing and emitting sensitive financial data, ensuring secure communication and data integrity becomes more challenging.
Example 3: Healthcare Systems
In a healthcare system, services might handle patient records, appointment scheduling, billing, and notifications. An overly complex event-driven design can lead to:
Data Inconsistency: If events are not processed in the correct order or if there are failures in event delivery, patient data might become inconsistent.
Maintenance Overhead: Keeping track of all the events and ensuring that each service is correctly processing them can become a significant maintenance burden.
Regulatory Compliance: Ensuring that the system complies with healthcare regulations (e.g., HIPAA) can be more difficult when data is flowing through numerous services and events.
Mitigation Strategies
To avoid these pitfalls, it is essential to:
Simplify Event Flows: Design events at the right level of abstraction and avoid creating too many fine-grained events.
Clear Service Boundaries: Define clear boundaries for each service and ensure that events are only produced and consumed within those boundaries.
Use Event Brokers: Employ event brokers or messaging platforms to decouple services and manage event routing more effectively.
Invest in Observability: Implement robust logging, monitoring, and tracing to track the flow of events and diagnose issues quickly.
“Simplicity is the soul of efficiency.” — Austin Freeman
By leveraging asynchrony and event-driven communication, EDA enables the construction of robust, scalable, and flexible systems that can handle complex workflows and real-time data processing.
Stackademic 🎓
Thank you for reading until the end. Before you go:
Please consider clapping and following the writer! 👏
This article is an outcome of a discussion with a fellow solution architect. We were discussing the different approaches or schools of thought a solution architect might follow. If there is some disagreement, we kindly ask that you respect our point of view, and we are open to any kind of healthy discussion on this topic.
“Good architecture is like a great novel: it gets better with every reading.” — Robert C. Martin
In the field of solution architecture, there are several approaches one might take. Among them are the Problem-First Approach, Design-First Approach, Domain-Driven Design (DDD), and Agile Architecture. Each has its own focus and methodology, and the choice of approach depends on the context and specific needs of the project.
“The goal of software architecture is to minimize the human resources required to build and maintain the required system.” — Robert C. Martin
Based on the various approaches discussed, we propose a common and effective order for a solution architect to follow:
1. Problem Statement
Define and Understand the Problem: Begin by clearly defining the problem that needs to be solved. This involves gathering requirements, understanding business needs, objectives, constraints, and identifying any specific challenges. This foundational step ensures that all subsequent efforts are aligned with solving the correct issue.
“In software, the most beautiful code, the most beautiful functions, and the most beautiful programs are sometimes not there at all.” — Jon Bentley
2. High-Level Design
Develop a Conceptual Framework: Create a high-level design that outlines the overall structure of the solution. Identify major components, their interactions, data flow, and the overall system architecture. This step provides a bird’s-eye view of the solution, ensuring that all stakeholders have a common understanding of the proposed system.
“The most important single aspect of software development is to be clear about what you are trying to build.” — Bjarne Stroustrup
3. Architecture Patterns
Select Suitable Patterns: Identify and choose appropriate architecture patterns that fit the high-level design and problem context. Patterns such as microservices, layered architecture, and event-driven architecture help ensure the solution is robust, scalable, and maintainable. Selecting the right pattern is crucial for addressing the specific needs and constraints of the project.
“A pattern is a solution to a problem in a context.” — Christopher Alexander
4. Technology Stacks
Choose Technologies: Select the technology stacks that will be used to implement the solution. This includes programming languages, frameworks, databases, cloud services, and other tools that align with the architecture patterns and high-level design. Consider factors like team expertise, performance, scalability, and maintainability. The choice of technology stack has a significant impact on the implementation and long-term success of the project.
“Any sufficiently advanced technology is indistinguishable from magic.” — Arthur C. Clarke
5. Low-Level Design
Detail Each Component: Create detailed, low-level designs for each component identified in the high-level design. Specify internal structures, interfaces, data models, algorithms, and detailed workflows. This step ensures that each component is well-defined and can be effectively implemented by development teams. Detailed design documents help in minimizing ambiguities and ensuring a smooth development process.
“Good design adds value faster than it adds cost.” — Thomas C. Gale
Summary of Order:
Practical Considerations:
Iterative Feedback and Validation: Incorporate iterative feedback and validation throughout the process. Regularly review designs with stakeholders and development teams to ensure alignment with business goals and to address any emerging issues. This iterative process helps in refining the solution and addressing any unforeseen challenges.
“You can’t improve what you don’t measure.” — Peter Drucker
Documentation: Maintain comprehensive documentation at each stage to ensure clarity and facilitate communication among stakeholders. Good documentation practices help in maintaining a record of decisions and the rationale behind them, which is useful for future reference and troubleshooting.
Flexibility: Be prepared to adapt and refine designs as new insights and requirements emerge. This approach allows for continuous improvement and alignment with evolving business needs. Flexibility is key to responding effectively to changing business landscapes and technological advancements.
“The measure of intelligence is the ability to change.” — Albert Einstein
Guidelines for Selecting an Approach
Here are some general guidelines for selecting an approach:
Problem-First Approach: This approach is suitable when the problem domain is well-understood, and the focus is on finding the best solution to address the problem. It works well for projects with clear requirements and constraints.
Design-First Approach: This approach is beneficial when the system’s architecture and design are critical, and upfront planning is necessary to ensure the system meets its quality attributes and non-functional requirements.
Domain-Driven Design (DDD): DDD is a good fit for complex domains with intricate business logic and evolving requirements. It promotes a deep understanding of the domain and helps in creating a maintainable and extensible system.
Agile Architecture: An agile approach is suitable when requirements are likely to change frequently, and the team needs to adapt quickly. It works well for projects with a high degree of uncertainty or rapidly changing business needs.
Ultimately, the choice of approach should be based on a careful evaluation of the project’s specific context, requirements, and constraints, as well as the team’s expertise and the organization’s culture and processes. It’s also common to combine elements from different approaches or tailor them to the project’s needs.
“The best way to predict the future is to invent it.” — Alan Kay
Real-Life Use Case: Netflix Microservices Architecture
A notable real-life example of following a structured approach in solution architecture is Netflix’s transition to a microservices architecture. Here’s how Netflix applied a similar order in their architectural approach:
1. Problem Statement
Netflix faced significant challenges with their existing monolithic architecture, including scalability issues, difficulty in deploying new features, and handling increasing loads as their user base grew globally. The problem was clearly defined: the need for a scalable, resilient, and rapidly deployable architecture to support their expanding services.
“If you define the problem correctly, you almost have the solution.” — Steve Jobs
2. High-Level Design
Netflix designed a high-level architecture that focused on breaking down their monolithic application into smaller, independent services. This conceptual framework provided a clear vision of how different components would interact and be managed. They aimed to achieve a highly decoupled system where services could be developed and deployed independently.
3. Architecture Patterns
Netflix chose a combination of several architectural patterns to meet their specific needs:
Microservices Architecture: This pattern allowed Netflix to create independent services that could be developed, deployed, and scaled individually. Each microservice handled a specific business capability and communicated with others through well-defined APIs. This pattern provided the robustness and scalability needed to handle millions of global users.
Event-Driven Architecture: Netflix implemented an event-driven architecture to handle asynchronous communication between services. This pattern was essential for maintaining responsiveness and reliability in a highly distributed system. Services are communicated via events, allowing the system to remain loosely coupled and scalable.
Circuit Breaker Pattern: Using tools like Hystrix, Netflix adopted the circuit breaker pattern to prevent cascading failures and to manage service failures gracefully. This pattern improved the resilience and fault tolerance of their architecture.
Service Discovery Pattern: Netflix utilized Eureka for service discovery. This pattern ensured that services could dynamically locate and communicate with each other, facilitating load balancing and failover strategies.
API Gateway Pattern: Zuul was employed as an API gateway, providing a single entry point for all client requests. This pattern helped manage and route requests to the appropriate microservices, improving security and performance.
4. Technology Stacks
Netflix selected a technology stack that included:
Java: For developing the core services due to its maturity, scalability, and extensive ecosystem.
Cassandra: For data storage, providing high availability and scalability across multiple data centers.
AWS: For cloud infrastructure, offering scalability, reliability, and a wide range of managed services.
Netflix also implemented additional tools and technologies to support their architecture patterns:
Hystrix: For implementing the circuit breaker pattern.
Eureka: For service discovery and registration.
Zuul: For API gateway and request routing.
Kafka: For event-driven messaging and real-time data processing.
Spinnaker: For continuous delivery and deployment automation.
5. Low-Level Design
Detailed designs for each microservice were created, specifying how they would interact with each other, handle data, and manage failures. This included defining:
APIs: Well-defined interfaces for communication between services.
Data Models: Schemas and structures for data storage and exchange.
Communication Protocols: RESTful APIs, gRPC, and event-based messaging.
Internal Structures: Detailed workflows, algorithms, and internal component interactions.
Each microservice was developed with clear boundaries and responsibilities, ensuring a well-structured implementation. Teams were organized around microservices, allowing for autonomous development and deployment cycles.
“The details are not the details. They make the design.” — Charles Eames
Practical Considerations
Netflix continuously incorporated iterative feedback and validation through extensive testing and monitoring. They maintained comprehensive documentation for their microservices, facilitating communication and understanding among teams. Flexibility was a core principle, allowing Netflix to adapt and refine their services based on real-time performance data and user feedback.
Iterative Feedback and Validation: Netflix used canary releases, A/B testing, and real-time monitoring to gather feedback and validate changes incrementally. This allowed them to make informed decisions and continuously improve their services.
Documentation: Detailed documentation was maintained for each microservice, including API specifications, architectural decisions, and operational guidelines. This documentation was essential for onboarding new team members and ensuring consistency across the organization.
Flexibility: The architecture was designed to be adaptable, allowing Netflix to quickly respond to changing requirements and scale services as needed. Continuous integration and continuous deployment (CI/CD) practices enabled rapid iteration and deployment.
“Flexibility requires an open mind and a welcoming of new alternatives.” — Deborah Day
By adopting a combination of architecture patterns and leveraging a robust technology stack, Netflix successfully transformed their monolithic application into a scalable, resilient, and rapidly deployable microservices architecture. This transition not only addressed their immediate challenges but also positioned them for future growth and innovation.
The approach a solution architect takes can significantly impact the success of a project. By following a structured process that starts with understanding the problem, moving through high-level and low-level design, and incorporating feedback and flexibility, a solution architect can create robust, scalable, and effective solutions. This methodology not only addresses immediate business needs but also lays a strong foundation for future growth and adaptability. The case of Netflix demonstrates how applying these principles can lead to successful, scalable, and resilient architectures that support business objectives and user demands.
Stackademic 🎓
Thank you for reading until the end. Before you go:
Please consider clapping and following the writer! 👏
The critical competencies of an architect are the foundation of their profession. They include a Strategic Mindset, Technical Acumen, Domain Knowledge, and Leadership capabilities. These competencies are not just buzzwords; they are essential attributes that define an architect’s ability to navigate and shape the built environment effectively.
Growth Path
The growth journey of an architect involves evolving expertise, which begins with a technical foundation and gradually expands into domain-specific knowledge before culminating in strategic leadership. This journey progresses through various stages, starting from the role of a Technical Architect, advancing through Solution and Domain Architect, and evolving into a Business Architect. The journey then peaks with the positions of Enterprise Architect and Chief Enterprise Architect. Each stage in this progression requires a deeper understanding and broader vision, reflecting the multifaceted nature of architectural practice.
Qualities of a Software Architect
Visual Thinking: Crucial for software architects, this involves the ability to conceptualize and visualize complex software systems and frameworks. It’s essential for effective communication and the realization of software architectural visions. By considering factors like system scalability, interoperability, and user experience, software architects craft visions that guide development teams and stakeholders, ensuring successful project outcomes.
Foundation in Software Engineering: A robust foundation in software engineering principles is vital for designing and implementing effective software solutions. This includes understanding software development life cycles, agile methodologies, and continuous integration/continuous deployment (CI/CD) practices, enabling software architects to build efficient, scalable, and maintainable systems.
Modelling Techniques: Mastery of software modelling techniques, such as Unified Modeling Language (UML) diagrams, entity-relationship diagrams (ERD), and domain-driven design (DDD), allows software architects to efficiently structure and communicate complexsystems. These techniques facilitate the clear documentation and understanding of software architecture, promoting better team alignment and project execution.
Infrastructure and Cloud Proficiency: Modern infrastructure, including cloud services (AWS, Azure, Google Cloud), containerization technologies (Docker, Kubernetes), and serverless architectures, is essential. This knowledge enables software architects to design systems that are scalable, resilient, and cost-effective, leveraging the latest in cloud computing and DevOps practices.
Security Domain Expertise: A deep understanding of cybersecurity principles, including secure coding practices, encryption, authentication protocols, and compliance standards (e.g., GDPR, HIPAA), is critical. Software architects must ensure the security and privacy of the applications they design, protecting them from vulnerabilities and threats.
Data Management and Analytics: Expertise in data architecture, including relational databases (RDBMS), NoSQL databases, data warehousing, big data technologies, and data streaming platforms, is crucial. Software architects need to design data strategies that support scalability, performance, and real-time analytics, ensuring that data is accessible, secure, and leveraged effectively for decision-making.
Leadership and Vision: Beyond technical expertise, the ability to lead and inspire development teams is paramount. Software architects must possess strong leadership qualities, fostering a culture of innovation, collaboration, and continuous improvement. They play a key role in mentoring developers, guiding architectural decisions, and aligning technology strategies with business objectives.
Critical and Strategic Thinking: Indispensable for navigating the complexities of software development, these skills enable software architects to address technical challenges, evaluate trade-offs, and make informed decisions that balance immediate needs with long-term goals.
Adaptive and Big Thinking: The ability to adapt to rapidly changing technology landscapes and think broadly about solutions is essential. Software architects must maintain a holistic view of their projects, considering not only the technical aspects but also market trends, customer needs, and business strategy. This broad perspective allows them to identify innovative opportunities and drive technological advancement within their organizations.
As software architects advance through their careers, from Technical Architect to Chief Enterprise Architect, they cultivate these essential qualities and competencies. This professional growth enhances their ability to impact projects and organizations significantly, leading teams to deliver innovative, robust, and scalable software solutions.
Stackademic 🎓
Thank you for reading until the end. Before you go:
Please consider clapping and following the writer! 👏
Enterprise software development is a dynamic and intricate field at the heart of modern business operations. This comprehensive guide explores the various aspects of enterprise software development, offering insights into how development teams collaborate, code, integrate, build, test, and deploy applications. Whether you’re an experienced developer or new to this domain, understanding the nuances of enterprise software development is crucial for achieving success.
1. The Team Structure
Team Composition: A typical development team comprises developers, a Scrum Master (if using Agile methodology), a project manager, software architects, and often, designers or UX/UI experts.
Software Architect Role: Software architects are crucial in designing the software’s high-level structure, ensuring scalability and adherence to best practices.
Client Engagement: The client is the vital link between end-users and developers, pivotal in defining project requirements.
Scaling Up: Larger projects may involve intricate team structures with multiple teams focusing on different software aspects, while core principles of collaboration, communication, and goal alignment remain steadfast.
2. Defining the Scope
Project Inception: Every enterprise software development project begins with defining the scope.
Client’s Vision: The client, often the product owner, communicates their vision and requirements, initiating the process of understanding what needs to be built and how it serves end-users.
Clear Communication: At this stage, clear communication and documentation are indispensable to prevent misunderstandings and ensure precise alignment with project objectives.
3. Feature Development Workflow
Feature Implementation: Developers implement features and functionalities outlined in the project scope.
Efficient Development: Teams frequently adopt a feature branch workflow, where each feature or task is assigned to a team of developers who work collaboratively on feature branches derived from the main codebase.
Code Review: Completing a feature triggers a pull request and code review, maintaining code quality, functionality, and adherence to coding standards.
4. Continuous Integration and Deployment
Modern Core: The heart of contemporary software development lies in continuous integration and deployment (CI/CD).
Seamless Integration: Developers merge feature branches into a development or main branch, initiating automated CI/CD pipelines that build, test, and deploy code to various environments.
Automation Benefits: Automation is pivotal in the deployment process to minimize human errors and ensure consistency across diverse environments.
5. Environment Management
Testing Grounds: Enterprise software often necessitates diverse testing and validation environments resembling the production environment.
Infrastructure as Code: Teams leverage tools like Terraform or AWS CloudFormation for infrastructure as code (IaC) to maintain consistency across environments.
6. Testing and Quality Assurance
Critical Testing: Testing is a critical phase in enterprise software development, encompassing unit tests, integration tests, end-to-end tests, performance tests, security tests, and user acceptance testing (UAT).
Robust Product: These tests ensure the delivery of a robust and reliable product.
7. Staging and User Feedback
Final Validation: A staging environment serves as a final validation platform before deploying new features.
User Engagement: Clients and end-users actively engage with the software, providing valuable feedback.
8. Release Management
Strategic Rollout: When stakeholders are content, a release is planned.
Feature Control: Feature flags or toggles enable controlled rollouts and easy rollbacks if issues arise.
9. Scaling and High Availability
Scalability Focus: Enterprise software often caters to large user bases and high traffic.
Deployment Strategies: Deployments in multiple regions, load balancing, and redundancy ensure scalability and high availability.
10. Bug Tracking and Maintenance
Ongoing Vigilance: Even after a successful release, software necessitates ongoing maintenance.
Issue Resolution: Bug tracking systems identify and address issues promptly as new features and improvements continue to evolve.