The Strangler Fig pattern is a design pattern used in microservices architecture to gradually replace a monolithic application with microservices. It is named after the Strangler Fig tree, which grows around a host tree, eventually strangling it. In this pattern, new microservices are developed alongside the existing monolithic application, gradually replacing its functionality until the monolith is no longer needed.
Key Steps
Transform: Identify a module or functionality within the monolith to be replaced by a new microservice. Develop the microservice in parallel with the monolith.
Coexist: Implement a proxy or API gateway to route requests to either the monolith or the new microservice. This allows both systems to coexist and ensures uninterrupted functionality.
Eliminate: Gradually shift traffic from the monolith to the microservice. Once the microservice is fully functional, the monolith can be retired.
Advantages
Incremental Migration: Minimizes risks associated with complete system rewrites.
Flexibility: Allows for independent development and deployment of microservices.
Reduced Disruptions: Ensures uninterrupted system functionality during the migration process.
Disadvantages
Complexity: Requires careful planning and coordination to manage both systems simultaneously.
Additional Overhead: Requires additional resources for maintaining both the monolith and the microservices.
Implementation
Identify Module: Select a module or functionality within the monolith to be replaced.
Develop Microservice: Create a new microservice to replace the identified module.
Implement Proxy: Configure an API gateway or proxy to route requests to either the monolith or the microservice.
Gradual Migration: Shift traffic from the monolith to the microservice incrementally.
Retire Monolith: Once the microservice is fully functional, retire the monolith.
Tools and Technologies
API Gateway: Used to route requests to either the monolith or the microservice.
Change Data Capture (CDC): Used to stream changes from the monolith to the microservice.
Event Streaming Platform: Used to create event streams that can be used by other applications.
Examples
E-commerce Application: Migrate order management functionality from a monolithic application to microservices using the Strangler Fig pattern.
Legacy System: Use the Strangler Fig pattern to gradually replace a legacy system with microservices.
The Strangler Fig pattern is a valuable tool for migrating monolithic applications to microservices. It allows for incremental migration, reduces disruptions, and minimizes risks associated with complete system rewrites. However, it requires careful planning and coordination to manage both systems simultaneously.
Stackademic 🎓
Thank you for reading until the end. Before you go:
Please consider clapping and following the writer! 👏
This article is an outcome of a discussion with a fellow solution architect. We were discussing the different approaches or schools of thought a solution architect might follow. If there is some disagreement, we kindly ask that you respect our point of view, and we are open to any kind of healthy discussion on this topic.
“Good architecture is like a great novel: it gets better with every reading.” — Robert C. Martin
In the field of solution architecture, there are several approaches one might take. Among them are the Problem-First Approach, Design-First Approach, Domain-Driven Design (DDD), and Agile Architecture. Each has its own focus and methodology, and the choice of approach depends on the context and specific needs of the project.
“The goal of software architecture is to minimize the human resources required to build and maintain the required system.” — Robert C. Martin
Based on the various approaches discussed, we propose a common and effective order for a solution architect to follow:
1. Problem Statement
Define and Understand the Problem: Begin by clearly defining the problem that needs to be solved. This involves gathering requirements, understanding business needs, objectives, constraints, and identifying any specific challenges. This foundational step ensures that all subsequent efforts are aligned with solving the correct issue.
“In software, the most beautiful code, the most beautiful functions, and the most beautiful programs are sometimes not there at all.” — Jon Bentley
2. High-Level Design
Develop a Conceptual Framework: Create a high-level design that outlines the overall structure of the solution. Identify major components, their interactions, data flow, and the overall system architecture. This step provides a bird’s-eye view of the solution, ensuring that all stakeholders have a common understanding of the proposed system.
“The most important single aspect of software development is to be clear about what you are trying to build.” — Bjarne Stroustrup
3. Architecture Patterns
Select Suitable Patterns: Identify and choose appropriate architecture patterns that fit the high-level design and problem context. Patterns such as microservices, layered architecture, and event-driven architecture help ensure the solution is robust, scalable, and maintainable. Selecting the right pattern is crucial for addressing the specific needs and constraints of the project.
“A pattern is a solution to a problem in a context.” — Christopher Alexander
4. Technology Stacks
Choose Technologies: Select the technology stacks that will be used to implement the solution. This includes programming languages, frameworks, databases, cloud services, and other tools that align with the architecture patterns and high-level design. Consider factors like team expertise, performance, scalability, and maintainability. The choice of technology stack has a significant impact on the implementation and long-term success of the project.
“Any sufficiently advanced technology is indistinguishable from magic.” — Arthur C. Clarke
5. Low-Level Design
Detail Each Component: Create detailed, low-level designs for each component identified in the high-level design. Specify internal structures, interfaces, data models, algorithms, and detailed workflows. This step ensures that each component is well-defined and can be effectively implemented by development teams. Detailed design documents help in minimizing ambiguities and ensuring a smooth development process.
“Good design adds value faster than it adds cost.” — Thomas C. Gale
Summary of Order:
Practical Considerations:
Iterative Feedback and Validation: Incorporate iterative feedback and validation throughout the process. Regularly review designs with stakeholders and development teams to ensure alignment with business goals and to address any emerging issues. This iterative process helps in refining the solution and addressing any unforeseen challenges.
“You can’t improve what you don’t measure.” — Peter Drucker
Documentation: Maintain comprehensive documentation at each stage to ensure clarity and facilitate communication among stakeholders. Good documentation practices help in maintaining a record of decisions and the rationale behind them, which is useful for future reference and troubleshooting.
Flexibility: Be prepared to adapt and refine designs as new insights and requirements emerge. This approach allows for continuous improvement and alignment with evolving business needs. Flexibility is key to responding effectively to changing business landscapes and technological advancements.
“The measure of intelligence is the ability to change.” — Albert Einstein
Guidelines for Selecting an Approach
Here are some general guidelines for selecting an approach:
Problem-First Approach: This approach is suitable when the problem domain is well-understood, and the focus is on finding the best solution to address the problem. It works well for projects with clear requirements and constraints.
Design-First Approach: This approach is beneficial when the system’s architecture and design are critical, and upfront planning is necessary to ensure the system meets its quality attributes and non-functional requirements.
Domain-Driven Design (DDD): DDD is a good fit for complex domains with intricate business logic and evolving requirements. It promotes a deep understanding of the domain and helps in creating a maintainable and extensible system.
Agile Architecture: An agile approach is suitable when requirements are likely to change frequently, and the team needs to adapt quickly. It works well for projects with a high degree of uncertainty or rapidly changing business needs.
Ultimately, the choice of approach should be based on a careful evaluation of the project’s specific context, requirements, and constraints, as well as the team’s expertise and the organization’s culture and processes. It’s also common to combine elements from different approaches or tailor them to the project’s needs.
“The best way to predict the future is to invent it.” — Alan Kay
Real-Life Use Case: Netflix Microservices Architecture
A notable real-life example of following a structured approach in solution architecture is Netflix’s transition to a microservices architecture. Here’s how Netflix applied a similar order in their architectural approach:
1. Problem Statement
Netflix faced significant challenges with their existing monolithic architecture, including scalability issues, difficulty in deploying new features, and handling increasing loads as their user base grew globally. The problem was clearly defined: the need for a scalable, resilient, and rapidly deployable architecture to support their expanding services.
“If you define the problem correctly, you almost have the solution.” — Steve Jobs
2. High-Level Design
Netflix designed a high-level architecture that focused on breaking down their monolithic application into smaller, independent services. This conceptual framework provided a clear vision of how different components would interact and be managed. They aimed to achieve a highly decoupled system where services could be developed and deployed independently.
3. Architecture Patterns
Netflix chose a combination of several architectural patterns to meet their specific needs:
Microservices Architecture: This pattern allowed Netflix to create independent services that could be developed, deployed, and scaled individually. Each microservice handled a specific business capability and communicated with others through well-defined APIs. This pattern provided the robustness and scalability needed to handle millions of global users.
Event-Driven Architecture: Netflix implemented an event-driven architecture to handle asynchronous communication between services. This pattern was essential for maintaining responsiveness and reliability in a highly distributed system. Services are communicated via events, allowing the system to remain loosely coupled and scalable.
Circuit Breaker Pattern: Using tools like Hystrix, Netflix adopted the circuit breaker pattern to prevent cascading failures and to manage service failures gracefully. This pattern improved the resilience and fault tolerance of their architecture.
Service Discovery Pattern: Netflix utilized Eureka for service discovery. This pattern ensured that services could dynamically locate and communicate with each other, facilitating load balancing and failover strategies.
API Gateway Pattern: Zuul was employed as an API gateway, providing a single entry point for all client requests. This pattern helped manage and route requests to the appropriate microservices, improving security and performance.
4. Technology Stacks
Netflix selected a technology stack that included:
Java: For developing the core services due to its maturity, scalability, and extensive ecosystem.
Cassandra: For data storage, providing high availability and scalability across multiple data centers.
AWS: For cloud infrastructure, offering scalability, reliability, and a wide range of managed services.
Netflix also implemented additional tools and technologies to support their architecture patterns:
Hystrix: For implementing the circuit breaker pattern.
Eureka: For service discovery and registration.
Zuul: For API gateway and request routing.
Kafka: For event-driven messaging and real-time data processing.
Spinnaker: For continuous delivery and deployment automation.
5. Low-Level Design
Detailed designs for each microservice were created, specifying how they would interact with each other, handle data, and manage failures. This included defining:
APIs: Well-defined interfaces for communication between services.
Data Models: Schemas and structures for data storage and exchange.
Communication Protocols: RESTful APIs, gRPC, and event-based messaging.
Internal Structures: Detailed workflows, algorithms, and internal component interactions.
Each microservice was developed with clear boundaries and responsibilities, ensuring a well-structured implementation. Teams were organized around microservices, allowing for autonomous development and deployment cycles.
“The details are not the details. They make the design.” — Charles Eames
Practical Considerations
Netflix continuously incorporated iterative feedback and validation through extensive testing and monitoring. They maintained comprehensive documentation for their microservices, facilitating communication and understanding among teams. Flexibility was a core principle, allowing Netflix to adapt and refine their services based on real-time performance data and user feedback.
Iterative Feedback and Validation: Netflix used canary releases, A/B testing, and real-time monitoring to gather feedback and validate changes incrementally. This allowed them to make informed decisions and continuously improve their services.
Documentation: Detailed documentation was maintained for each microservice, including API specifications, architectural decisions, and operational guidelines. This documentation was essential for onboarding new team members and ensuring consistency across the organization.
Flexibility: The architecture was designed to be adaptable, allowing Netflix to quickly respond to changing requirements and scale services as needed. Continuous integration and continuous deployment (CI/CD) practices enabled rapid iteration and deployment.
“Flexibility requires an open mind and a welcoming of new alternatives.” — Deborah Day
By adopting a combination of architecture patterns and leveraging a robust technology stack, Netflix successfully transformed their monolithic application into a scalable, resilient, and rapidly deployable microservices architecture. This transition not only addressed their immediate challenges but also positioned them for future growth and innovation.
The approach a solution architect takes can significantly impact the success of a project. By following a structured process that starts with understanding the problem, moving through high-level and low-level design, and incorporating feedback and flexibility, a solution architect can create robust, scalable, and effective solutions. This methodology not only addresses immediate business needs but also lays a strong foundation for future growth and adaptability. The case of Netflix demonstrates how applying these principles can lead to successful, scalable, and resilient architectures that support business objectives and user demands.
Stackademic 🎓
Thank you for reading until the end. Before you go:
Please consider clapping and following the writer! 👏
Back in the 2020s, a project requirement came my way that was both challenging and interesting. My manager and I were very new to the company, so the success of this project was crucial for us. Although the technical stack of this project was relatively simple, it holds a special place in my heart for many reasons. In this article, I aim to share my experience and journey with it. This article is not about the how-to steps; rather, I want to share about mindset and culture on a personal level and as a team.
“The only way to do great work is to love what you do.” — Steve Jobs
The challenges were manifold: there was no budget or only a minimal budget available, a shortage of technical team members, and a need to deliver in a very short timeframe. Sounds interesting, right? I was thrilled by the requirement.
“Start where you are. Use what you have. Do what you can.” — Arthur Ashe
The high-level project details are as follows: From an upstream application to an Oracle-based application, we needed to transfer data downstream in JSON format. The backend-to-frontend relationship of the upstream application is one-to-many, meaning the backend Oracle data has multiple frontend views to represent the data based on business use or objects. Therefore, the data pipeline needed the capacity to transform Oracle-based data into many front-end views, necessitating mapping the data with XML configuration for the front end. The daily transaction volume was not too large, but a decent amount of 3 million records.
Oversimplified/high-level
“It always seems impossible until it’s done.” — Nelson Mandela
Since we had no budget or resource strength, I decided to explore open-source and no-code or low-code solutions. After a day or two of research, I decided to use Apache NiFi and MongoDB. The idea was to reverse-engineer the current upstream application using NiFi, which means NiFi would read data from Oracle and simultaneously map those data according to the frontend configuration stored in XML for the frontend application.
“Teamwork is the ability to work together toward a common vision. The ability to direct individual accomplishments toward organizational objectives. It is the fuel that allows common people to attain uncommon results.” — Andrew Carnegie
When I first presented this solution to the team and management, the initial response was not very positive. Except for my manager, most stakeholders expressed doubts, which is understandable since most of them were hearing about Apache NiFi for the first time, and their experience lay primarily in Oracle and Java. MongoDB was also new to them. Normally, people think about “how” first, but I was focused on “why” and “what” before “how.”
After several rounds of discussion, including visual flowcharts and small prototypes, everyone agreed on the tech stack and the solution.
This led to the next challenge: the team we assembled had never worked with these tech stacks. To move forward, we needed to build a production-grade platform. I started by reading books and devised infrastructure build steps for both NiFi and MongoDB clusters. It was challenging, and there were extensive troubleshooting sessions, but we finally built our platform.
“Data Engineering with Python: Work with massive datasets to design data models and automate data pipelines using Python” by Paul Crickard. Even though we use Groovy for scripting and not Python, this book helped us understand Apache NiFi in greater detail. I remember those days; I used to carry this book with me everywhere I went, even to the park and while waiting for signals on the road. Thanks to the author, Paul Crickard.
“Don’t watch the clock; do what it does. Keep going.” — Sam Levenson
The team was very small, comprising two Java developers and two Linux developers, all new to these tech stacks. Once the platform was ready, my next task was to train our developers to bring them up to speed. Fortunately, I found a book that helped me with Apache NiFi, and for MongoDB, I took a MongoDB University course. I filtered the required information for my team to learn. There were also challenges, as my team was in China and I was in the North American timezone, requiring me to work mostly at night to help my team.
Another challenge that later became an advantage was communication. My Chinese team was not very comfortable with verbal explanations, so I decided to share knowledge through visual aids like flowcharts and diagrams, along with developing small prototypes for them to try and walk through. This approach helped a lot later on, as I learned how to represent complex topics in simple diagrams, a skill I use in my articles today.
“What you get by achieving your goals is not as important as what you become by achieving your goals.” — Zig Ziglar
The lucky factor was that my team was extremely hardworking and quick learners. They adapted to the new tech stack in minimal time. In three months, we built the first end-to-end MVP and presented a full demo to the business, which was a huge success. Three months later, we scaled the application to production-grade and delivered our first release. Today, this team is the fastest in the release cycle and operates independently.
“It is not mandatory for a Solution Architect to be an SME in any specific tool or technology. Instead, he or she should be a strategic thinker, putting “why” and “what” first and adapting quickly to take advantage of opportunities where we can add value to the business or end user despite all limitations and trade-offs.” — Shanoj Kumar V
“Success is not the key to happiness. Happiness is the key to success. If you love what you are doing, you will be successful.” — Albert Schweitzer
Stackademic 🎓
Thank you for reading until the end. Before you go:
Please consider clapping and following the writer! 👏
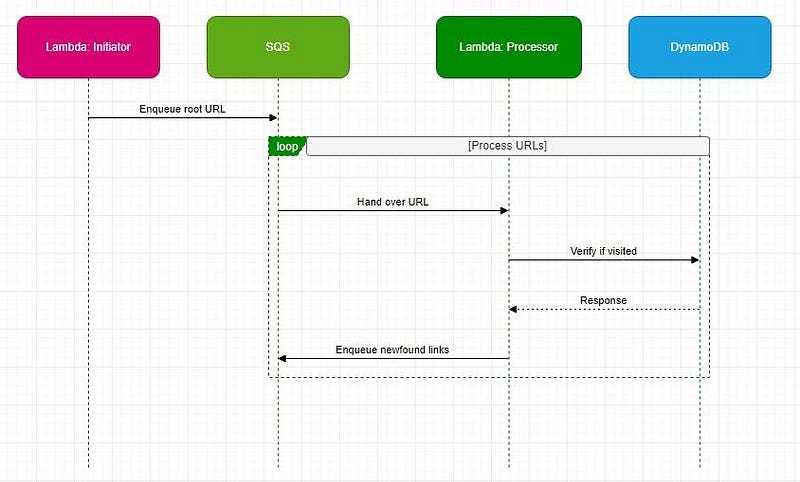
The main components of our serverless crawler are Lambda functions, an SQS queue, and a DynamoDB table. Here’s a breakdown:
Lambda: Two distinct functions — one for initiating the crawl and another for the actual processing.
SQS: Manages pending crawl tasks as a buffer and task distributor.
DynamoDB: Stores visited URLs, ensuring we avoid redundant visits.
Workflow & Logic Rationale:
Initiation:
Starting Point (Root URL):
Logic: The crawl starts with a root URL, e.g., “www.shanoj.com”.
Rationale: A defined beginning allows the crawler to commence in a guided manner.
Uniqueness with UUID:
Logic: A unique run ID is generated for every crawl to ensure distinction.
Rationale: These guards against potential data overlap in the case of concurrent crawls.
Avoiding Redundant Visits:
Logic: The root URL is pre-emptively marked as “visited”.
Rationale: This step is integral to maximizing efficiency by sidestepping repeated processing.
The URL then finds its way to SQS, awaiting crawling.
Processing:
Link Extraction:
Logic: A secondary Lambda function polls SQS for URLs. Once a URL is retrieved, the associated webpage is fetched. All the links are identified and extracted within this webpage for further processing.
Rationale: Extracting all navigable paths from our current location is pivotal to web exploration.
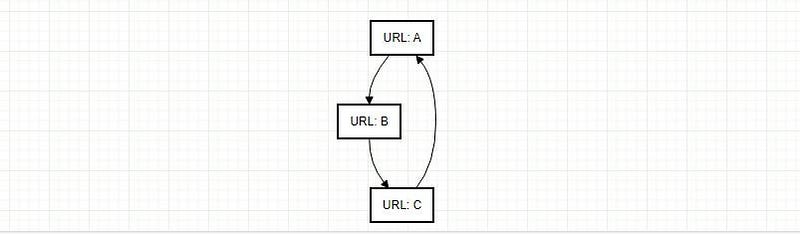
Depth-First Exploration Strategy:
Logic: Extracted links undergo a check against DynamoDB. If previously unvisited, they’re designated as such in the database and enqueued back into SQS.
Rationale: This approach delves deep into one link’s pathways before backtracking, optimizing resource utilization.
Special Considerations:
A challenge for web crawlers is the potential for link loops, which can usher in infinite cycles. By verifying the “visited” status of URLs in DynamoDB, we proactively truncate these cycles.
Here’s a behind-the-scenes look at creating a URL-shortening service using Amazon Web Services (AWS).
Users and System Interaction:
User Requests: Users submit a long web address wanting a shorter version, or they might want to use a short link to reach the original website or remove a short link.
API Gateway: This is AWS’s reception. It directs user requests to the right service inside AWS.
Lambda Functions: These are the workers. They perform tasks like making a link shorter, retrieving the original from a short link, or deleting a short link.
DynamoDB: This is the storage room. All the long and short web addresses are stored here.
ElastiCache: Before heading to DynamoDB, the system checks here first when users access a short link. It’s faster.
VPC & Subnets: This is the AWS structure. The welcoming part (API Gateway) is public, while sensitive data (DynamoDB) is kept private and secure.
Making Links Shorter for Users:
Sequential Counting: Every web link gets a unique number. To keep it short, that number is converted into a combination of letters and numbers.
Hashing: The system also shortens the long web address into a fixed-length string. This method may produce similar results for different links, but the system manages and differentiates them efficiently.
Sequential Counting: This takes a long URL as input and uses a unique counter value from the database to generate a short URL.
Enhanced Uniqueness & Collision Handling: Sequential counting ensures uniqueness, and in the unlikely event of a hashing collision, the sequential identifier can be used as a fallback or combined with the hash.
Balancing Predictability & Compactness: Hashing gives compact URLs, and by adding a sequential component, we reduce predictability.
Scalability & Performance: Sequential lookups are faster. If the hash table grows large, the performance could degrade due to hash collisions. Combining with sequential IDs ensures fast retrievals.
Return to API Gateway: The system redirects users to the original Long URL.
Lambda Function for Deleting (DELETE Request)
Input: The user provides a short URL they want to delete.
Check-in DynamoDB: System looks up the short URL in DynamoDB.
URL Found: If the URL mapping for the short URL is found, it proceeds to deletion.
Delete from DynamoDB: The system deletes the URL mapping from DynamoDB.
Clear from ElastiCache: The System also clears the URL mapping from the cache to ensure that the short URL no longer redirects users.
Return Confirmation to API Gateway: After the deletion is successful, a confirmation is sent to the API Gateway, confirming the user about the deletion.
Simple Math Behind Our URL Shortening (Envelope Estimation):
When we use a 6-character mix of letters (both small and capital) and numbers for our short URLs, we have about 56.8 billion different combinations. If users create 100 million short links every day, we can keep making unique links for over 500 days without repeating them.
In Plain English
Thank you for being a part of our community! Before you go: