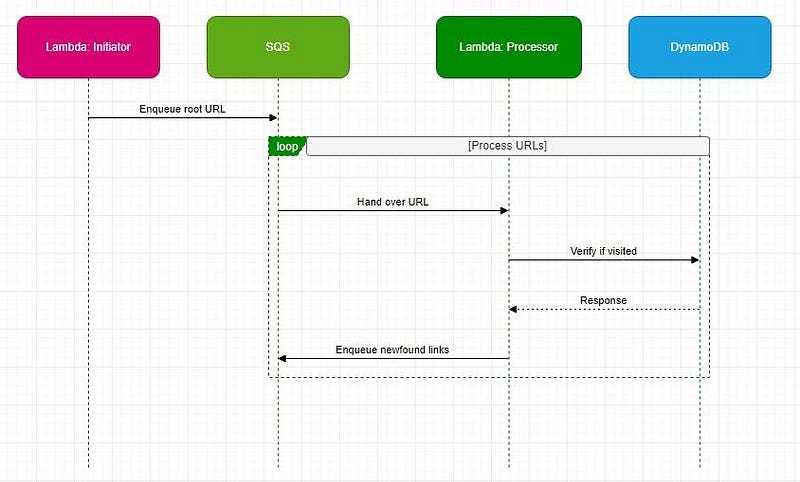
API, short for Application Programming Interface, is a fundamental concept in software development. It establishes well-defined methods for communication between software components, enabling seamless interaction. APIs define how software components communicate effectively.
Key Concepts in APIs:
- Interface vs. Implementation: An API defines an interface through which one software piece can interact with another, just like a user interface allows users to interact with software.
- APIs are for Software Components: APIs primarily enable communication between software components or applications, providing a standardized way to send and receive data.
- API Address: An API often has an address or URL to identify its location, which is crucial for other software to locate and communicate with it. In web APIs, this address is typically a URL.
- Exposing an API: When a software component makes its API available, it “exposes” the API. Exposed APIs allow other software components to interact by sending requests and receiving responses.
Different Types of APIs:
Let’s explore the four main types of APIs: Operating System API, Library API, Remote API, and Web API.
Operating System API
An Operating System API enables applications to interact with the underlying operating system. It allows applications to access essential OS services and functionalities.
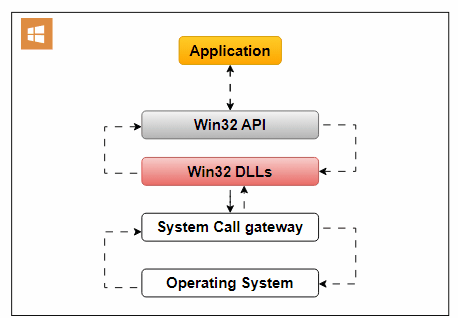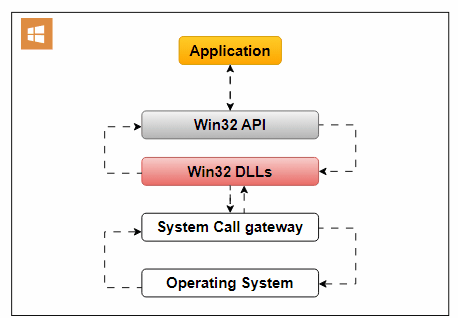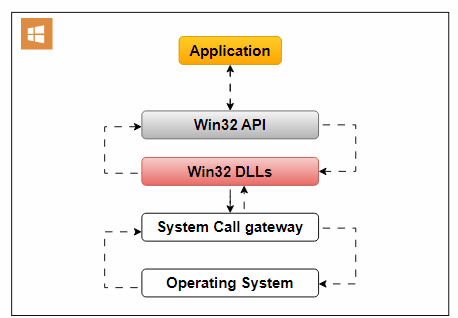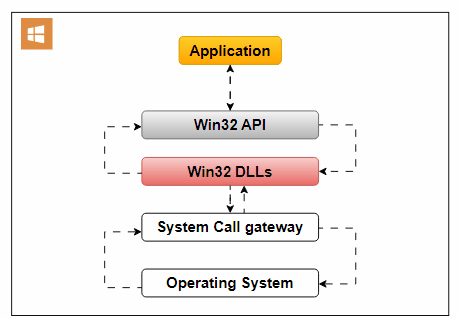
Use Cases:
- File Access: Applications often require file system access for reading, writing, or managing files. The Operating System API facilitates this interaction.
- Network Communication: To establish network connections for data exchange, applications rely on the OS’s network-related services.
- User Interface Elements: Interaction with user interface elements like windows, buttons, and dialogues is possible through the Operating System API.
An example of an Operating System API is the Win32 API, designed for Windows applications. It offers functions for handling user interfaces, file operations, and system settings.
Library API
Library APIs allow applications to utilize external libraries or modules simultaneously. These libraries provide additional functionalities, enhancing applications.

Use Cases:
- Extending Functionality: Applications often require specialized functionalities beyond their core logic. Library APIs enable the inclusion of these functionalities.
- Code Reusability: Developers can reuse pre-built code components by using libraries, saving time and effort.
- Modularity: Library APIs promote modularity in software development by separating core functionality from auxiliary features.
For example, an application with a User library may incorporate logging capabilities through a Logging library’s API.
Remote API
Remote APIs enable communication between software components or applications distributed over a network. These components may not run in the same process or server.

Key Features:
- Network Communication: Remote APIs facilitate communication between software components on different machines or servers.
- Remote Proxy: One component creates a proxy (often called a Remote Proxy) to communicate with the remote component. This proxy handles network protocols, addressing, method signatures, and authentication.
- Platform Consistency: Client and server components using a Remote API must often be developed using the same platform or technology stack.
Examples of Remote APIs include DCOM, .NET Remoting, and Java RMI (Remote Method Invocation).
Web API
Web APIs allow web applications to communicate over the Internet based on standard protocols, making them interoperable across platforms, OSs, and programming languages.
Key Features:
- Internet Communication: Web APIs enable web apps to interact with remote web services and exchange data over the Internet.
- Platform-Agnostic: Web APIs support web apps developed using various technologies, promoting seamless interaction.
- Widespread Popularity: Web APIs are vital in modern web development and integration.
Use Cases:
- Data Retrieval: Web apps can access Web APIs to retrieve data from remote services, such as weather information or stock prices.
- Action Execution: Web APIs allow web apps to perform actions on remote services, like posting a tweet on Twitter or updating a user’s profile on social media.
Types of Web APIs
Now, let’s explore four popular approaches for building Web APIs: SOAP, REST, GraphQL, and gRPC.
- SOAP (Simple Object Access Protocol): Is a protocol for exchanging structured information to implement web services, relying on XML as its message format. Known for strict standards and reliability, it is suitable for enterprise-level applications requiring ACID-compliant transactions.

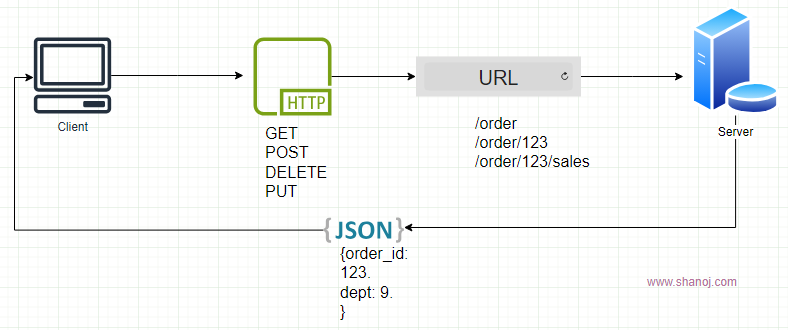
- REST (Representational State Transfer): This architectural style uses URLs and data formats like JSON and XML for message exchange. It is simple, stateless, and widely used in web and mobile applications, emphasizing simplicity and scalability.
- GraphQL: Developed by Facebook, GraphQL provides flexibility in querying and updating data. Clients can specify the fields they want to retrieve, reducing over-fetching and enabling real-time updates.

- gRPC (Google Remote Procedure Call): Developed by Google, gRPC is based on HTTP/2 and Protocol Buffers (protobuf). It excels in microservices architectures and scenarios involving streaming or bidirectional communication.

Real-World Use Cases:
- Operating System API: An image editing software accesses the file system for image manipulation.
- Library API: A web application leverages the ‘TensorFlow’ library API to integrate advanced machine learning capabilities for sentiment analysis of user-generated content.
- Remote API: A ride-sharing service connects distributed passenger and driver apps.
- Web API: An e-commerce site provides real-time stock availability information.
- SOAP: A banking app that handles secure financial transactions.
- REST: A social media platform exposes a RESTful API for third-party developers.
- GraphQL: A news content management system that enables flexible article queries.
- gRPC: An online gaming platform that maintains real-time player-server communication.
APIs are vital for effective software development, enabling various types of communication between software components. The choice of API type depends on specific project requirements and use cases. Understanding these different API types empowers developers to choose the right tool for the job.
If you enjoyed reading this and would like to explore similar content, please refer to the following link:
“REST vs. GraphQL: Tale of Two Hotel Waiters” by Shanoj Kumar V
Stackademic
Thank you for reading until the end. Before you go:
- Please consider clapping and following the writer! 👏
- Follow us on Twitter(X), LinkedIn, and YouTube.
- Visit Stackademic.com to find out more about how we are democratizing free programming education around the world.