Change data capture is an advanced technology for data replication and loading that reduces data warehousing programs’ time and resource costs and facilitates real-time data integration across the enterprise. By detecting changed records in data sources in real-time and propagating those changes to an ETL data warehouse, change data capture can sharply reduce the warehouse’s need for bulk load updating.
Why do you need to capture and move the changes in your data?
• Populating centralized databases, data marts, data warehouses, or data lakes
• Enabling machine learning, advanced analytics and AI on modern data architectures like Hadoop and Spark
• Enabling queries, reports, business intelligence or analytics without production impact
• Feeding real-time data to employee, customer or partner applications
• Keeping data from siloed databases in sync
• Reducing the impact of database maintenance, backup or testing
• Re-platforming to new database or operating systems
• Consolidating databases
How does Talend CDC work?
Talend CDC is based on a publish/subscribe model, where the publisher captures the changes in data in real-time. Then it makes it available to the subscribers which can be databases or applications.
The Oracle Database records changes in the transaction log in commit order by assigning a System Commit Number (SCN) to every transaction.
Three different CDC modes are available in Talend Studio:
• Trigger: this mode is the by-default mode used by CDC components.
• Redo/Archive log: this mode is used with Oracle v11 and previous versions.
• XStream: this mode is used only with Oracle v12 with OCI.

Benefits of Log-Based Change Data Capture:
• Redo/Archive log: this mode is used with Oracle v11 and previous versions
• XStream: this mode is used only with Oracle v12 with OCI
The biggest benefit of log-based change data capture is the asynchronous nature of CDC:
Changes are captured independent of the source application performing the changes.
• The additional performance impact on the source system is low
• CDC enables the implementation of near real-time architectures
• No significant changes to the application in the source system CDC reduces the amount of data transmitted over the network
About Oracle Xstream:
XStream consists of Oracle Database components and application programming interfaces (APIs) that enable client applications to receive data changes from an Oracle database and send data changes to an Oracle database.
These data changes can be shared between Oracle databases and other systems. The other systems include non-Oracle databases, non-RDBMS Oracle products, file systems, third party software applications,and so on. A client application is designed by the user for specific purposes and use cases.
XStream consists of two major features: XStream Out and XStream In.
XStream Out provides Oracle Database components and APIs that enable you to share data changes made to an Oracle database with other systems. XStream Out can retrieve both data manipulation language (DML) and data definition language (DDL) changes from the redo log and send these changes to a client application that uses the APIs.
XStream In provides Oracle Database components and APIs that enable you to share data changes made to other systems with an Oracle database. XStream can apply these changes to database objects in the Oracle database
Reference:
https://help.talend.com/r/6lpaT_M~MEVrltFQcrPe4g/Ni3tTLbdYnf7GCwNT5F5rQ
http://docs.oracle.com/cd/E11882_01/server.112/e16545/toc.htm










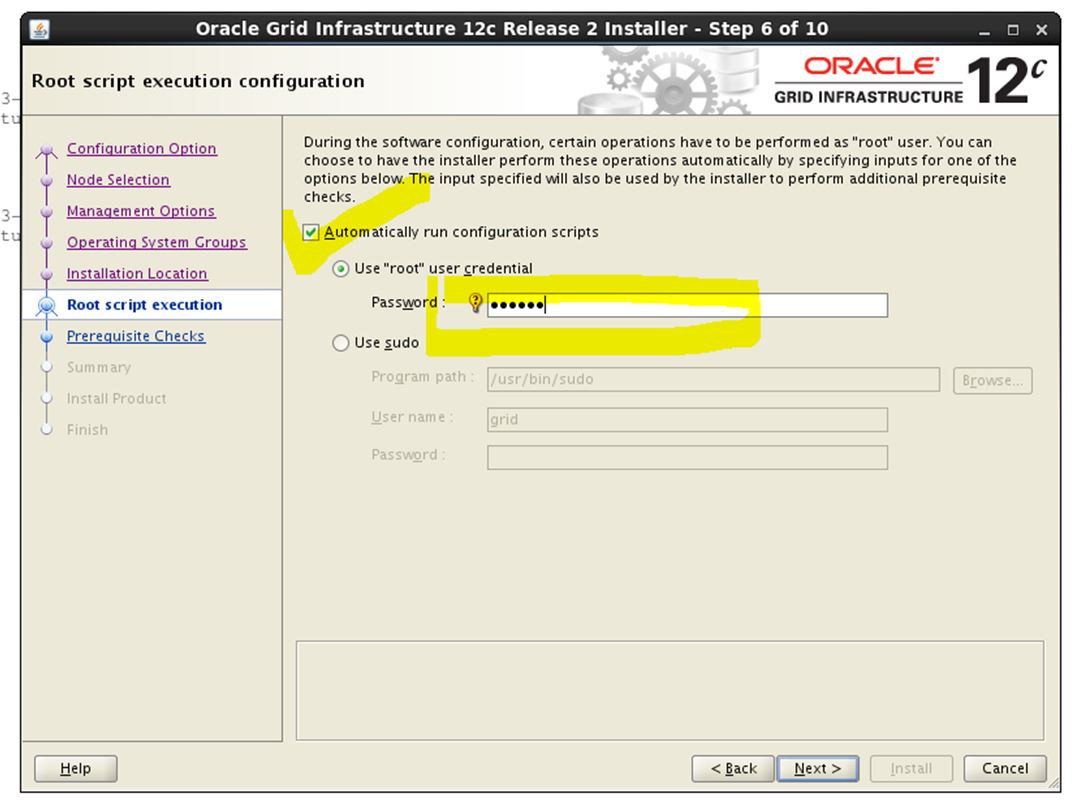 Mark the check box “Automatically run configuration scripts”
Mark the check box “Automatically run configuration scripts”